- An Introduction to Machine Learning | The Complete Guide
- Data Preprocessing for Machine Learning | Apply All the Steps in Python
- Regression
- Learn Simple Linear Regression in the Hard Way(with Python Code)
- Multiple Linear Regression in Python (The Ultimate Guide)
- Polynomial Regression in Two Minutes (with Python Code)
- Support Vector Regression Made Easy(with Python Code)
- Decision Tree Regression Made Easy (with Python Code)
- Random Forest Regression in 4 Steps(with Python Code)
- 4 Best Metrics for Evaluating Regression Model Performance
- Classification
- A Beginners Guide to Logistic Regression(with Example Python Code)
- K-Nearest Neighbor in 4 Steps(Code with Python & R)
- Support Vector Machine(SVM) Made Easy with Python
- Kernel SVM for Dummies(with Python Code)
- Naive Bayes Classification Just in 3 Steps(with Python Code)
- Decision Tree Classification for Dummies(with Python Code)
- Random forest Classification
- Evaluating Classification Model performance
- A Simple Explanation of K-means Clustering in Python
- Hierarchical Clustering
- Association Rule Learning | Apriori
- Eclat Intuition
- Reinforcement Learning in Machine Learning
- Upper Confidence Bound (UCB) Algorithm: Solving the Multi-Armed Bandit Problem
- Thompson Sampling Intuition
- Artificial Neural Networks
- Natural Language Processing
- Deep Learning
- Principal Component Analysis
- Linear Discriminant Analysis (LDA)
- Kernel PCA
- Model Selection & Boosting
- K-fold Cross Validation in Python | Master this State of the Art Model Evaluation Technique
- XGBoost
- Convolution Neural Network
- Dimensionality Reduction
Random Forest Regression in 4 Steps(with Python Code) | Machine Learning

In this tutorial, we will understand the decision tree regression algorithm and implement it in Python.
What is a Random Forest?
Random Forest is a supervised learning algorithm. The basic idea behind Random Forest is that it combines multiple decision trees to determine the final output. That is it builds multiple decision trees and merges their predictions together to get a more accurate and stable prediction.
How Does Random Forest Work?
.It uses the ensemble learning technique(Ensemble learning is using multiple algorithms at a time or a single algorithm multiple times to make a model more powerful) to build several decision trees at random data points. Then their predictions are averaged. Taking the average value of predictions made by several decision trees is usually better than that of a single decision tree. Look at the following illustration of two trees(though the number of trees is much more!)
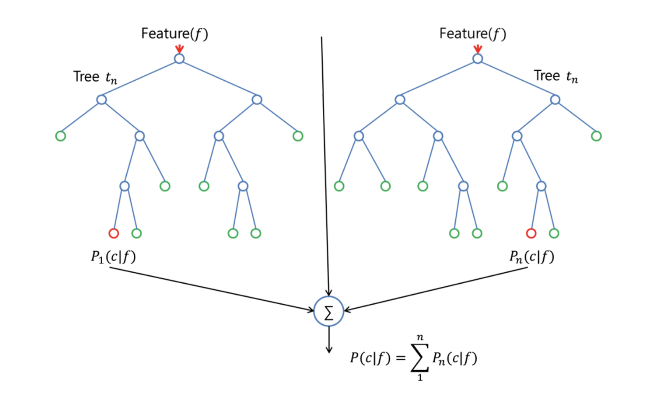
What is Random in Random Forest?
Random forest uses 'randomness' in two cases-
- Random Sample Selection Random tree ensembles a set of decision trees. While training an individual decision tree, a random sample of training data is used. This method is called bootstrapping where many data sets are developed from the original data set by taking random samples. This way random forest could train more and more decision trees.
- Random Variable Selection During each split, a random subset of features is examined. Then the set of variables that would provide the best split is chosen for the split. This random selection reduces the correlations among the trees and improves the predictive performance of the model.
The Steps Required to Perform Random Forest Regression
Step 1: Pick at random k data points from the training set.
Step 2: Build the decision Tree associated with this K data point.
Step 3: Choose the number Ntree of trees you want to build and repeat STEPS 1 & 2.
Step 4: For a new data point, make each one of our Ntree trees predict the value of Y for the data point in question and assign the new data point the average across all of the predicted Y values.
Now let's do these steps in Python.
Implementing Random Forest Regression in Python
In this tutorial, we will implement Random Forest Regression in Python. We will work on a dataset (Position_Salaries.csv) that contains the salaries of some employees according to their Position. Our task is to predict the salary of an employee at an unknown level. So we will make a Regression model using Random Forest technique for this task.
You can download the dataset from here.
First of all, we will import some essential libraries. You will get the code in Google Colab also.
# Importing the Essential Libraries import numpy as np import matplotlib.pyplot as plt
import pandas as pd
Then we will import the dataset.
# Importing the Dataset dataset = pd.read_csv("Position_Salaries.csv")Now our dataset has imported into our program. Let's check how it looks:
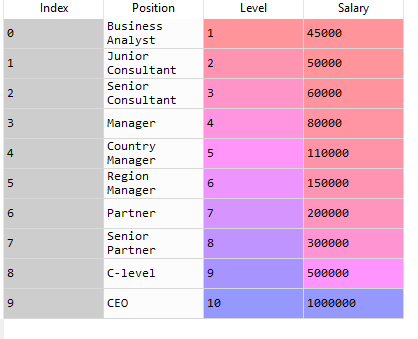
Now, we need to determine the dependent and independent variables. Here we can see the Level is an independent variable while Salary is the dependent variable or target variable as we want to find out the salary of an employee according to his Level. So our feature matrix X will contain the Level column and the value of Salary is taken into the dependent variable vector, y.
# Creating Feature Matrix and Dependent Variable Vector X = dataset.iloc[:, 1:2].values y = dataset.iloc[:, 2].values
Well, we have come to the main part of the Regression. To implement Random Forest Regression, we need RandomForestRegressor class from Scikit-Learn library.
Check that we did not normalize or scale the data. Is not scaling necessary in random forest?
The answer is no. Random forest is a tree-based algorithm that does not require convergence and numerical precision of data. Unlike other distance-based algorithms such as k-nearest neighbors, where scaling is required so that the priority is not given to specific features.
If you still apply feature scaling to your data, the result will be the same as before. So, why bother?
Just fit the model to the random forest regressor.
from sklearn.ensemble import RandomForestRegressor regressor = RandomForestRegressor(n_estimators = 10, random_state = 0) regressor.fit(X, y)
Note: Here, n_estimators is a parameter that sets the number of decision trees created for a random data point(the default value is 10, you can use a more number of trees). random_state = 0 is used so that your code provides the same output as us.
Our model is ready! Now, we will test our model for a new value of y.
# Predicting a New Value y_pred = regressor.predict([[6.5]])
Our model predicted a value of $167k. Let's compare this value with the actual value. For this, we will visualize our training set result.
# Visualizing the Training Set X_grid = np.arange(min(X), max(X), 0.01) X_grid = X_grid.reshape((len(X_grid), 1)) plt.scatter(X, y, color = 'red') plt.plot(X_grid, regressor.predict(X_grid), color = 'blue') plt.title('Truth or Bluff (Random Forest Regression)') plt.xlabel('Position level') plt.ylabel('Salary') plt.show() 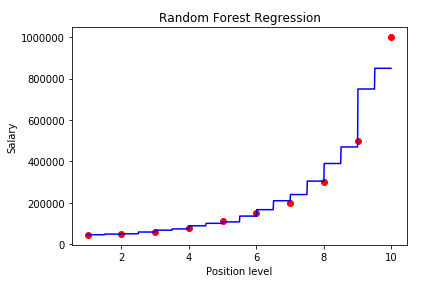
After executing the code, we can see a graph, which is pretty similar to that of a Decision Tree Regression. The main difference is that the lines are more discontinuous from the Decision Tree regression. This is because Random Forest uses a number of decision trees to predict the value of a data point.
From the graph, we see that the prediction for a 6.5 level is pretty close to the actual value(around $160k).
Improving the Accuracy of Random Forest Regression
We have built a very simple model. There are many things that can be done to make a more improved model. Let's look at them-
- Add More Data For the sake of simplicity, we took a small data set. To make a more robust and well-performing model you should add more data. As the random forest model uses multiple decision trees, more data will increase the variance, eventually leading to a better predictive model.
- Better Data Preprocessing Before feeding to the model, handle missing values properly. You should check if the data contain outliers. Outliers can seriously damage your model accuracy. Remove outliers to build a better-performing model.
- Use Feature Selection Methods You should feed the model with the most appropriate features it requires to make a good model. For this, you can use some feature selection techniques to remove redundant and correlated features. Then feed the data to the random forest model.
- Apply Cross-Validation Random forest resembles a set of individual trees and take their average predictions in the final model. Hence, there are some chances that data overlap (same data being used in many trees) which will lead to overfitting the model. You should use some sort of cross-validation technique to make sure the model does not overfit.
- Hyperparameter Tuning Random forest algorithm uses a number of hyperparameters. You need to carefully choose the best hyperparameters to make the best model. User grid search or random search methods to find the best hyperparameters to build the perfect model.
Decision Trees Vs. Random Forest
Random Forest is a collection of Decision Trees, but there are some differences. If you input a training dataset with features and labels into a decision tree, it will formulate some set of rules, which will be used to make the predictions.
Another difference is that decision trees might suffer from Overfitting. Random Forest prevents overfitting most of the time, by creating random subsets of the features and building smaller trees using these subsets. Afterward, it combines the subtrees. Note that this doesn't work every time and that it also makes the computation slower, depending on how many trees your random forest builds.
Random Forest is a flexible, easy to use machine learning algorithm that produces, even without hyper-parameter tuning, a great result most of the time. It is also one of the most used algorithms because of its simplicity and the fact that it can be used for both classification and regression tasks. In this post, you are going to learn, how the random forest algorithm works and several other important things about it.
Final Words
In this tutorial, I have tried to explain all the aspects of random forest regression. The key takeaways of the tutorial are-
- What random is forest and how it works
- Implementation in Python
- Ways to improve the random forest model
Hope this tutorial helped you to understand all the concepts. You have any questions about the concepts, please ask me in the comments.
Happy Machine Learning!