- An Introduction to Machine Learning | The Complete Guide
- Data Preprocessing for Machine Learning | Apply All the Steps in Python
- Regression
- Learn Simple Linear Regression in the Hard Way(with Python Code)
- Multiple Linear Regression in Python (The Ultimate Guide)
- Polynomial Regression in Two Minutes (with Python Code)
- Support Vector Regression Made Easy(with Python Code)
- Decision Tree Regression Made Easy (with Python Code)
- Random Forest Regression in 4 Steps(with Python Code)
- 4 Best Metrics for Evaluating Regression Model Performance
- Classification
- A Beginners Guide to Logistic Regression(with Example Python Code)
- K-Nearest Neighbor in 4 Steps(Code with Python & R)
- Support Vector Machine(SVM) Made Easy with Python
- Kernel SVM for Dummies(with Python Code)
- Naive Bayes Classification Just in 3 Steps(with Python Code)
- Decision Tree Classification for Dummies(with Python Code)
- Random forest Classification
- Evaluating Classification Model performance
- A Simple Explanation of K-means Clustering in Python
- Hierarchical Clustering
- Association Rule Learning | Apriori
- Eclat Intuition
- Reinforcement Learning in Machine Learning
- Upper Confidence Bound (UCB) Algorithm: Solving the Multi-Armed Bandit Problem
- Thompson Sampling Intuition
- Artificial Neural Networks
- Natural Language Processing
- Deep Learning
- Principal Component Analysis
- Linear Discriminant Analysis (LDA)
- Kernel PCA
- Model Selection & Boosting
- K-fold Cross Validation in Python | Master this State of the Art Model Evaluation Technique
- XGBoost
- Convolution Neural Network
- Dimensionality Reduction
Linear Discriminant Analysis (LDA) | Machine Learning
Linear Discriminant Analysis (LDA): Linear Discriminant Analysis(LDA) is a dimensionality reduction technique, that separates the best classes that are related to the dependent variable. Which makes it a supervised algorithm. In PCA, we do not consider the dependent variable. So this is the basic difference between the PCA and LDA algorithms.
If there are n number of independent variables, the LDA algorithm will extract p<=n new independent variables that separate most of the classes of the dependent variable.
LDA in Python: LDA is a very simple and popular algorithm in practice. In this tutorial, we will implement this algorithm alongside with Logistic Regression algorithm. For this task, we will use the famous "Wine.csv" dataset from the UCI machine learning repository. Our version of dataset contains thirteen independent variables that represent various aspects of wines and one dependent variable that represent the three types of buyers of the wine based on specific features. Now, we will implement LDA to reduce the number of independent variables to a predefined value (i.e. two).
You can download the whole dataset from here. You will get the full code in Google Colab also.
First of all, we will import some essential libraries.
# Importing the libraries import numpy as np import matplotlib.pyplot as plt import pandas as pd
Then we will import our dataset and make the feature matrix and dependent variable vector.
# Importing the dataset dataset = pd.read_csv('Wine.csv') X = dataset.iloc[:, 0:13].values y = dataset.iloc[:, 13].valuesNow, we will split the dataset into training and test sets.
# Splitting the dataset into the Training set and Test set from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
Let's apply feature scaling onto the dataset.
# Feature Scaling from sklearn.preprocessing import StandardScaler sc = StandardScaler() X_train = sc.fit_transform(X_train) X_test = sc.transform(X_test)
We have come to the main part of our program. Now, we will implement the LDA algorithm to the dataset.
# Applying LDA from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA lda = LDA(n_components = 2) X_train = lda.fit_transform(X_train, y_train) X_test = lda.transform(X_test)
Note: n_component is the parameter that represents the number of independent variables we want in our model. Here we take it to 2, so our model will contain two independent variables.
Let's fit a linear regression algorithm to our model.
# Fitting Logistic Regression to the Training set from sklearn.linear_model import LogisticRegression classifier = LogisticRegression(random_state = 0) classifier.fit(X_train, y_train) # Predicting the Test set results y_pred = classifier.predict(X_test)
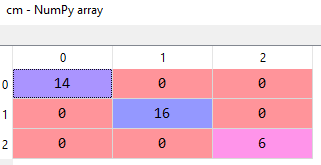
Now, let's see how well our model is to make predictions using the confusion matrix.
# Making the Confusion Matrix from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_test, y_pred)
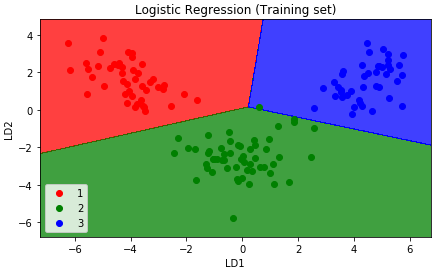
Let's visualize the prediction of our model for both training and test sets.
# Visualising the Training set results from matplotlib.colors import ListedColormap X_set, y_set = X_train, y_train X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01), np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01)) plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green', 'blue'))) plt.xlim(X1.min(), X1.max()) plt.ylim(X2.min(), X2.max()) for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1], c = ListedColormap(('red', 'green', 'blue'))(i), label = j) plt.title('Logistic Regression (Training set)') plt.xlabel('LD1') plt.ylabel('LD2') plt.legend() plt.show()The graph will look like the following illustration
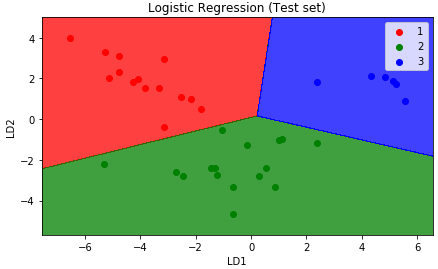
# Visualising the Test set results from matplotlib.colors import ListedColormap X_set, y_set = X_test, y_test X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01), np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01)) plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green', 'blue'))) plt.xlim(X1.min(), X1.max()) plt.ylim(X2.min(), X2.max()) for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1], c = ListedColormap(('red', 'green', 'blue'))(i), label = j) plt.title('Logistic Regression (Test set)') plt.xlabel('LD1') plt.ylabel('LD2') plt.legend() plt.show()
The output graph will be-