- An Introduction to Machine Learning | The Complete Guide
- Data Preprocessing for Machine Learning | Apply All the Steps in Python
- Regression
- Learn Simple Linear Regression in the Hard Way(with Python Code)
- Multiple Linear Regression in Python (The Ultimate Guide)
- Polynomial Regression in Two Minutes (with Python Code)
- Support Vector Regression Made Easy(with Python Code)
- Decision Tree Regression Made Easy (with Python Code)
- Random Forest Regression in 4 Steps(with Python Code)
- 4 Best Metrics for Evaluating Regression Model Performance
- Classification
- A Beginners Guide to Logistic Regression(with Example Python Code)
- K-Nearest Neighbor in 4 Steps(Code with Python & R)
- Support Vector Machine(SVM) Made Easy with Python
- Kernel SVM for Dummies(with Python Code)
- Naive Bayes Classification Just in 3 Steps(with Python Code)
- Decision Tree Classification for Dummies(with Python Code)
- Random forest Classification
- Evaluating Classification Model performance
- A Simple Explanation of K-means Clustering in Python
- Hierarchical Clustering
- Association Rule Learning | Apriori
- Eclat Intuition
- Reinforcement Learning in Machine Learning
- Upper Confidence Bound (UCB) Algorithm: Solving the Multi-Armed Bandit Problem
- Thompson Sampling Intuition
- Artificial Neural Networks
- Natural Language Processing
- Deep Learning
- Principal Component Analysis
- Linear Discriminant Analysis (LDA)
- Kernel PCA
- Model Selection & Boosting
- K-fold Cross Validation in Python | Master this State of the Art Model Evaluation Technique
- XGBoost
- Convolution Neural Network
- Dimensionality Reduction
Natural Language Processing | Machine Learning
Natural Language Processing: Natural language processing (NLP) is a field of artificial intelligence concerned with the interactions between computers and human(natural) language.
In a simple sense, Natural language Processing is applying machine learning to text and language to teach computers to understand what is said in spoken and written words. The main focus of NLP is to read, decipher, understand and make sense of the human language in a manner that is useful.
Examples of NLP in Real Life: You will find a lot of applications of NLP in your life. Here we name a few-
Translating one language to another i.e. Google Translator
Checking grammatical errors i.e. Microsoft word or Grammarly applies NLP to check and correct grammatical errors.
Sentiment analysis that is identifying the mood or subjective opinions of a text
Summarizing a text or article
Predicting the genre of books
Speech recognition which is used in virtual assistants such as Apple Siri, Google Assistant, and Amazon Alexa
Question answering
How NLP Works?
Most NLP algorithms are classification models, and they include Logistic Regression, Naive Bayes, CART which is a model based on decision trees, Maximum Entropy and other classification algorithms to predict the outcome.
The working procedure of NLP can be divided into three major steps:
Step 1: Preprocessing of text that includes Cleaning the data, Tokenizing, Stemming, Parts of Speech(POS) Tagging, Lemmatization, Named Entity Recognition (NER)
Step 2: This step is for vectorizing data, that is encoding text into integer i.e. numeric form to create a feature vector.
Step 3: The final step is to fit a suitable classification algorithm to the dataset and make the predictions.
We can implement all these steps using NLP libraries. Some of the popular NLP libraries are-
Natural Language Toolkit-NLTK
SpaCy
Stanford NLP
OpenNLP
In this article, we are going to implement all these steps using the NLTK library and classification algorithm. From this part, you will learn how to-
Clean texts to prepare them for the Machine Learning models,
Create a Bag of Words model,
Apply Machine Learning models onto this Bag of Worlds model.
Natural Language Processing in Python: Now, we will perform the steps of NLP in Python. For this task, we are going to use Restaurant_Reviews.tsv dataset. The dataset contains 1000 reviews from customers. These reviews are identified with values 0 and 1 whether they are positive or negative. 0 means the review is positive and 1 means the review is positive. Let's have a glimpse of that dataset.
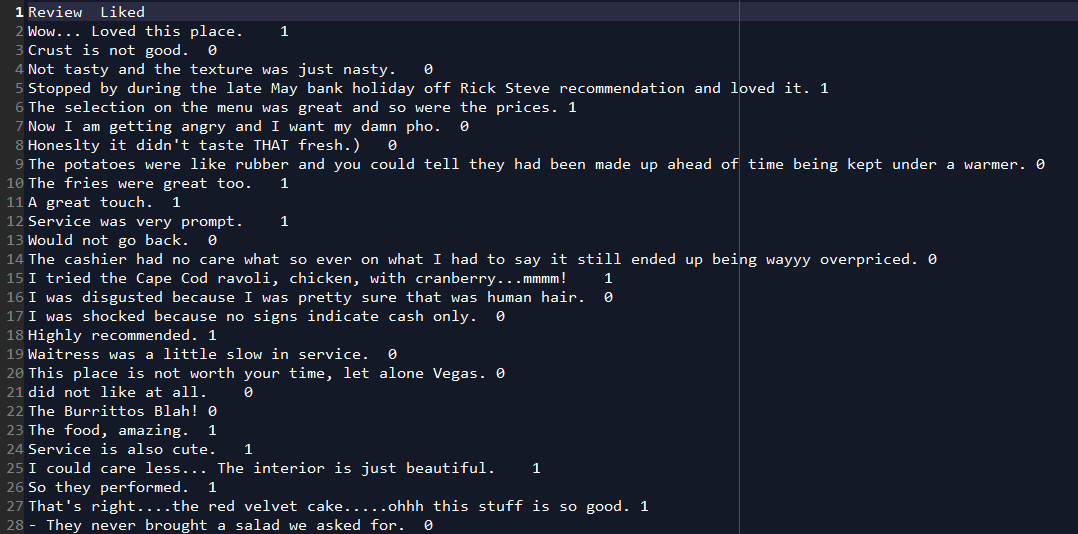
This dataset looks different than other datasets as it is in tsv(tab-separated value) format. For NLP task we can not use csv(comma-separated value) files. This is because of the strings may contain commas, which will confuse our model.
You can download the whole dataset from here.
It contains two columns namely Review and Liked. They are separated by a tab. Now our task is to preprocess this data. Then we will implement any of the classification algorithms to classify the reviews whether it is positive or negative.
First of all, we will import some essential libraries. You will get the code in Google Colab also.
# Importing the libraries import numpy as np import matplotlib.pyplot as plt import pandas as pd
Now we will import the dataset.
# Importing the dataset dataset = pd.read_csv('Restaurant_Reviews.tsv', delimiter = '\t', quoting = 3)As our dataset is in tsv format, we need to clarify that in the delimiter parameter. The reviews contain double quotes, which may cause confusion to the model. So we set the quoting parameter to 3 to avoid this problem.
Now, we will clean the texts using the NLTK library from Python. The texts contain a lot of useless words which have no impact on the characteristic of the review, we need to get rid of those words like wow, place, texture, etc. Then we need to perform stemming that is we will take the root of a word like loved, loving, lovely, etc. all can be replaced by the same word love. The texts also contain some common words like was, that, this, it, is, etc. which are known as stopwords and have no use at all. So we will remove those words using the stopwords package from the NLTK library. We only consider the English words and also take all the words into lowercase.
# Cleaning the texts import re import nltk nltk.download('stopwords') from nltk.corpus import stopwords from nltk.stem.porter import PorterStemmer corpus = [] for i in range(0, 1000): review = re.sub('[^a-zA-Z]', ' ', dataset['Review'][i]) review = review.lower() review = review.split() ps = PorterStemmer() review = [ps.stem(word) for word in review if not word in set(stopwords.words('english'))] review = ' '.join(review) corpus.append(review)# Creating the Bag of Words model from sklearn.feature_extraction.text import CountVectorizer cv = CountVectorizer(max_features = 1500) X = cv.fit_transform(corpus).toarray() y = dataset.iloc[:, 1].values
After doing all these steps, the corpus will now look like this-
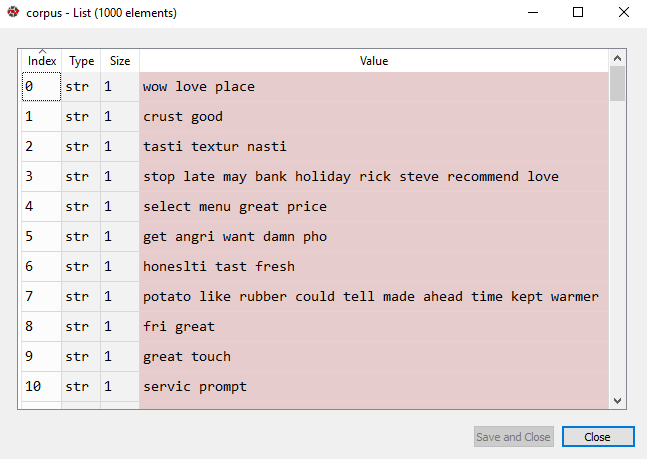
We have completed preprocessing the texts and creating the bag of words model. Now, we split this preprocessed dataset into training and test sets.
# Splitting the dataset into the Training set and Test set from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = 0)
Let's fit a classification algorithm into our training set. Here we will use Naive Bayes which is one of the most popular and most effective classification algorithms for NLP.
# Fitting Naive Bayes to the Training set from sklearn.naive_bayes import GaussianNB classifier = GaussianNB() classifier.fit(X_train, y_train)
Now, we will perform a prediction on the test set.
# Predicting the Test set results y_pred = classifier.predict(X_test)
Let's see how good is our model in performing predictions using the confusion matrix.
# Making the Confusion Matrix from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_test, y_pred)

From the above confusion matrix, we can see that the accuracy of our model is 73%.