- An Introduction to Machine Learning | The Complete Guide
- Data Preprocessing for Machine Learning | Apply All the Steps in Python
- Regression
- Learn Simple Linear Regression in the Hard Way(with Python Code)
- Multiple Linear Regression in Python (The Ultimate Guide)
- Polynomial Regression in Two Minutes (with Python Code)
- Support Vector Regression Made Easy(with Python Code)
- Decision Tree Regression Made Easy (with Python Code)
- Random Forest Regression in 4 Steps(with Python Code)
- 4 Best Metrics for Evaluating Regression Model Performance
- Classification
- A Beginners Guide to Logistic Regression(with Example Python Code)
- K-Nearest Neighbor in 4 Steps(Code with Python & R)
- Support Vector Machine(SVM) Made Easy with Python
- Kernel SVM for Dummies(with Python Code)
- Naive Bayes Classification Just in 3 Steps(with Python Code)
- Decision Tree Classification for Dummies(with Python Code)
- Random forest Classification
- Evaluating Classification Model performance
- A Simple Explanation of K-means Clustering in Python
- Hierarchical Clustering
- Association Rule Learning | Apriori
- Eclat Intuition
- Reinforcement Learning in Machine Learning
- Upper Confidence Bound (UCB) Algorithm: Solving the Multi-Armed Bandit Problem
- Thompson Sampling Intuition
- Artificial Neural Networks
- Natural Language Processing
- Deep Learning
- Principal Component Analysis
- Linear Discriminant Analysis (LDA)
- Kernel PCA
- Model Selection & Boosting
- K-fold Cross Validation in Python | Master this State of the Art Model Evaluation Technique
- XGBoost
- Convolution Neural Network
- Dimensionality Reduction
Association Rule Learning | Apriori | Machine Learning
In this tutorial, we are going to understand the association rule learning and implement the Apriori algorithm in Python.
Association Rule Learning: Association rule learning is a machine learning method that uses a set of rules to discover interesting relations between variables in large databases i.e. the transaction database of a store. It identifies frequent associations among variables called association rules that consist of an antecedent (if) and a consequent (then).
For example, if a person buys a burger, then there is a chance that he will buy some french fries too. This is because there is some relationship between french fries and burgers (they are often taken together).
The task of association rule learning is to discover this kind of relationship and identify the rules of their association.
Association rule learning algorithms are used extensively in data mining for market basket analysis, which is determining dependencies among various products purchased by the customers at different times analyzing the customer transaction databases.
There are two basic types of Association learning algorithms- Apriori and Eclat. In this article, we are going to implement the Apriori algorithm.
Apriori Intuition: This is a classic algorithm in data mining. It is used for analyzing frequent item sets and relevant association rules. It can operate on databases containing a lot of transactions.
Let's take an example of transactions made by customers in a grocery shop.
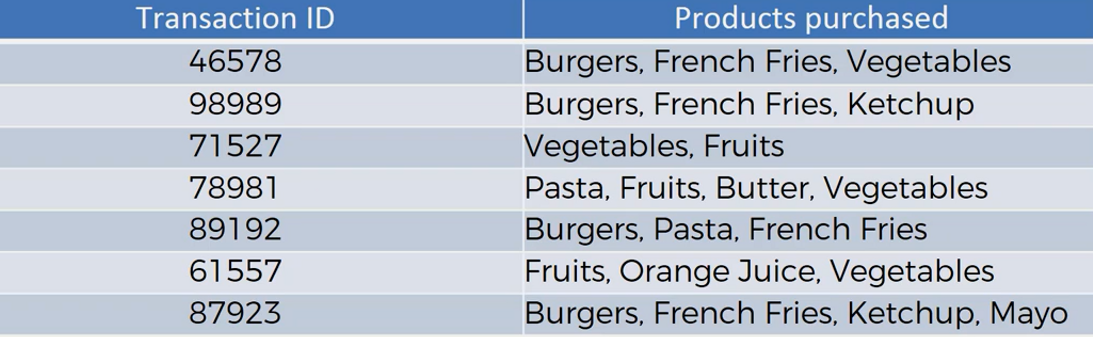
From the above transactions, the potential association rules can be
If the customer buys Burgers can also buy French fries
If the customer buys Vegetable can also buy Fruits
If the customer buys Pasta can also buy Butter
These associations are measured using three common metrics- Support, Confidence and lift.
Support: Support is the rate of the frequency of an item that appears in the total number of items. Like the frequency of burgers among all the transactions. Mathematically, for an item I,
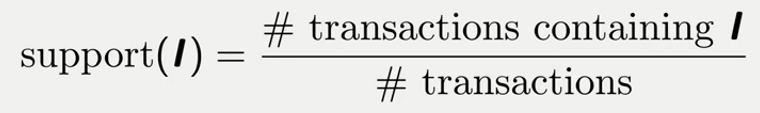
Confidence: Confidence is the conditional probability of occurrence of a consequent (then) providing the occurrence of an antecedent (if). It's kind of testing a rule. Like if a customer buys a burger(antecedent), he is supposed to buy french fries(consequent). Mathematically, the confidence of l2 given l1 will be

Lift: Lift is the ratio of confidence and support. It tells how likely an item is purchased after another item is purchased. Simply it is the likelihood to buy french fries if a customer buys a burger. Mathematically,
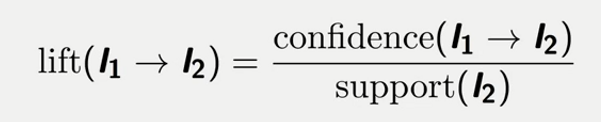
Step 1: Set a minimum support and confidence.
Step 2: Take all the subsets in transactions having support than minimum support.
Step 3: Take all the rules of these subsets having higher confidence than minimum confidence.
Step 4: Sort the rules by decreasing lift.
Let's apply these steps one by one to the above example
First, we will calculate the frequency table for the itemset
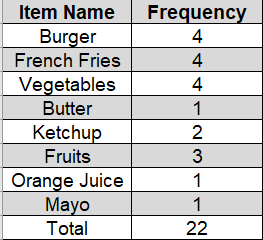
Let's say we need to find the association rule for Burger->French fries
Step 1: let's say we have set the minimum support and confidence to 15%. That means no items having support less than 15% will be incurred.
Then we are left with the following items.
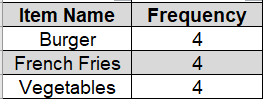
Step 2: Now our possible subsets for the above itemsets will be {Burger, French Fries}, {Burger, Vegetables}, {French Fries, Vegetables} etc.
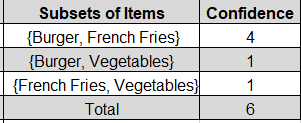
Step 3: For our threshold value of confidence, we are left with one pair or one rule. And that is {Burger, French Fries} or Burger --> French Fries
Step 4: As we are left with only one rule we calculate the lift for this rule and that is approximately 3.7
Implementation in Python: Now, we will implement the Apriori algorithm in Python. For this task, we are using a dataset called "Market_Basket_Optimization.csv" that contains the transaction of different products by customers from a grocery store. Now, we need to implement the Apriori algorithm to find out some potential association rules among the products.
You can download the dataset from here. You will get the code in Google Colab also.
First of all, we will import the essential libraries.
# Importing the libraries import numpy as np import matplotlib.pyplot as plt import pandas as pd
The next step is to preprocess our data. The dataset preserves the transaction of different products by a single customer in a separate row. So we need to treat the columns as the name of the products, not as a header. For that, we will remove the take no header in the dataset. The Apriori algorithm works with strings, which means we need to make a list of string values from the dataset. To do so, we will implement the str function from Python.
# Data Preprocessing dataset = pd.read_csv('Market_Basket_Optimisation.csv', header = None) transactions = [] for i in range(0, 7501): transactions.append([str(dataset.values[i,j]) for j in range(0, 20)]) Now, we reach the part where we will train our dataset with the Apriori algorithm. To use the Apriori class in our program we need to have the apyori.py an open-source python module for the Apriori algorithm.
You can find the module here.
In the class, we need to take the list of transactions as a parameter. The crucial step of performing Apriori is to set the minimum value for the support, confidence and lift. To find the most valuable association rules, we need the perfect combination of these values. Otherwise, the association rules will not be useful.
For our dataset, we have found that the combination of 30% support and 20% confidence as minimum values is perfect. But these values vary across different datasets and business problems. So, you should carefully observe the dataset to set these values.
The minimum length is set to two which means we want associations among at least two products.
# Training Apriori on the dataset from apyori import apriori rules = apriori(transactions, min_support = 0.003, min_confidence = 0.2, min_lift = 3, min_length = 2)
Now, we will see how our model performs to find potential association rules.
# Visualising the results results = list(rules)
This will generate a list like the following. This is a list of all the potential rules upon the given constraints.
.png)