- An Introduction to Machine Learning | The Complete Guide
- Data Preprocessing for Machine Learning | Apply All the Steps in Python
- Regression
- Learn Simple Linear Regression in the Hard Way(with Python Code)
- Multiple Linear Regression in Python (The Ultimate Guide)
- Polynomial Regression in Two Minutes (with Python Code)
- Support Vector Regression Made Easy(with Python Code)
- Decision Tree Regression Made Easy (with Python Code)
- Random Forest Regression in 4 Steps(with Python Code)
- 4 Best Metrics for Evaluating Regression Model Performance
- Classification
- A Beginners Guide to Logistic Regression(with Example Python Code)
- K-Nearest Neighbor in 4 Steps(Code with Python & R)
- Support Vector Machine(SVM) Made Easy with Python
- Kernel SVM for Dummies(with Python Code)
- Naive Bayes Classification Just in 3 Steps(with Python Code)
- Decision Tree Classification for Dummies(with Python Code)
- Random forest Classification
- Evaluating Classification Model performance
- A Simple Explanation of K-means Clustering in Python
- Hierarchical Clustering
- Association Rule Learning | Apriori
- Eclat Intuition
- Reinforcement Learning in Machine Learning
- Upper Confidence Bound (UCB) Algorithm: Solving the Multi-Armed Bandit Problem
- Thompson Sampling Intuition
- Artificial Neural Networks
- Natural Language Processing
- Deep Learning
- Principal Component Analysis
- Linear Discriminant Analysis (LDA)
- Kernel PCA
- Model Selection & Boosting
- K-fold Cross Validation in Python | Master this State of the Art Model Evaluation Technique
- XGBoost
- Convolution Neural Network
- Dimensionality Reduction
K-fold Cross Validation in Python | Master this State of the Art Model Evaluation Technique | Machine Learning
Evaluation of machine learning models is important. To build a state of the art machine learning model, you need to make sure the accuracy of your model on every test set is as good as the accuracy it has obtained from the training set.
Usually, we take a data set, split it into train and test sets. We use the training set to train the model and the test set to evaluate the performance of the model. But it is not a good approach as in production, the model would come across data quite different from the test set. Which eventually lead to degrading the performance of the model, making our evaluation faulty.
To solve this problem, we can use cross-validation techniques such as k-fold cross-validation. Cross-validation is a statistical method used to compare and evaluate the performance of Machine Learning models.
In this tutorial, we are going to learn the K-fold cross-validation technique and implement it in Python. Let's dive into the tutorial!
What is K-fold Cross Validation?
While building machine learning models, we randomly split the dataset into training and test sets where a maximum percentage of the data is taken into the training set. Though the test dataset is small, there is still some chance that we left some important data in there that might have improved the model. And there is a problem of high variance in the training set. Here where the idea of K-fold cross-validation comes in handy. In K-fold Cross-Validation, the training set is randomly split into K(usually between 5 to 10) subsets known as folds. Where K-1 folds are used to train the model and the other fold is used to test the model. This technique improves the high variance problem in a dataset as we are randomly selecting the training and test folds.
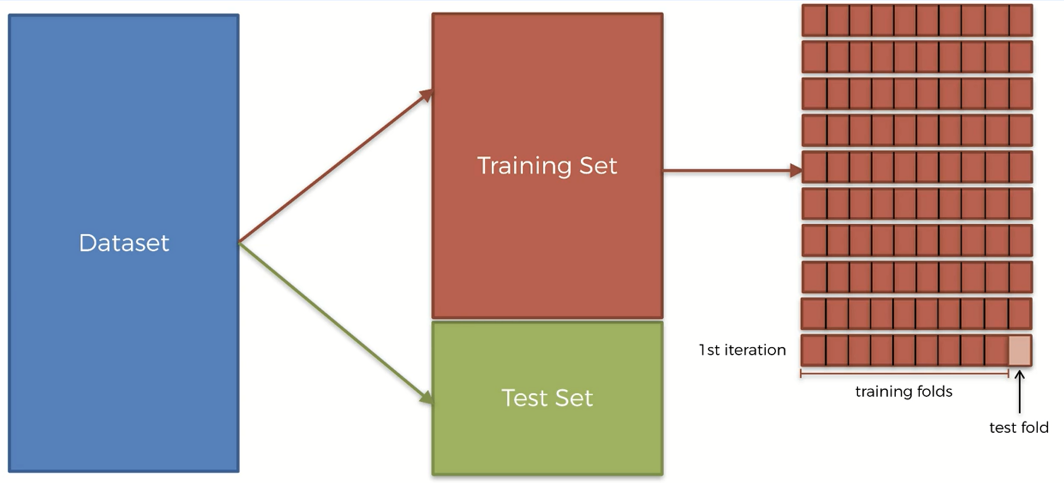 The steps required to perform K-fold cross-validation are given below-
The steps required to perform K-fold cross-validation are given below-
Step 1: Split the entire data randomly in k folds(usually between 5 to 10). The higher number of splits leads to a less biased model. Step 2: Then fit the model with k-1 folds and test it with the remaining Kth fold. Record the performance metric. Step 3: Repeat step 2 until every k-fold serves as the test set. Step 4: Take the average of all the recorded scores. This will serve as the final performance metric of your model.
Implementing K-fold Cross Validation in Python
Now, we will implement this technique to validate our machine-learning model. For this task, we are using "Social_Network_Ads.csv" dataset.You can download the dataset from here.
This is a classification task. And for this, we will build a Kernel SVM classification model. You will get the code in Google Colab also.
First, we will use the conventional method, randomly split the dataset into training and test set, train the model, and evaluate it on the test set.
Then We will implement the K-fold cross-validation technique to improve our model.
First of all, we need to import some essential libraries.
# Importing the libraries import numpy as np import matplotlib.pyplot as plt import pandas as pd
Now, we will import the dataset and make the feature matrix X and the dependent variable vector y.
# Importing the dataset dataset = pd.read_csv('Social_Network_Ads.csv') X = dataset.iloc[:, [2, 3]].values y = dataset.iloc[:, 4].values Now, we will split the dataset into training and test sets.
# Splitting the dataset into Training set and Test set from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
We, need to feature scale our training and test sets for an improved result.
# Feature Scaling from sklearn.preprocessing import StandardScaler sc = StandardScaler() X_train = sc.fit_transform(X_train) X_test = sc.transform(X_test)
Now, we will fit Kernel SVM into our training set and predict how it performs on the test set.
# Fitting Kernel SVM to the Training set from sklearn.svm import SVC classifier = SVC(kernel = 'rbf', random_state = 0) classifier.fit(X_train, y_train) # Predicting the Test set results
y_pred = classifier.predict(X_test)
To calculate the accuracy of our Kernel SVM model we will build the confusion matrix.
# Making the Confusion Matrix from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_test, y_pred)
Let's see how accurate our model is .png)
From the above matrix, we can see that the accuracy of our Kernel SVM model is 93% Now, let's see how we can improve the performance metric of our model using K-fold cross-validation with k = 10 folds.
# Applying k-Fold Cross Validation from sklearn.model_selection import cross_val_score accuracies = cross_val_score(estimator = classifier, X = X_train, y = y_train, cv = 10) accuracies.mean() accuracies.std()
Let's see the accuracies for all the folds.
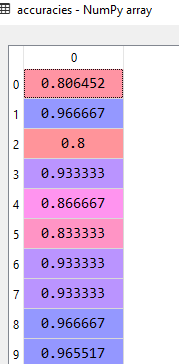
The mean value for the accuracies is 90% with a mean deviation of 6%. That means our model is accurate for 96% or 84% time.
Choosing the Number of Folds
It depends on how much CPU power you have or willing to spend. A lower value of K means less variance which leads to more bias. And having a higher value means more variance and lower bias.
The computational cost for different values is the primary concern while choosing the value. A higher K value requires more computational time and power and vice versa. Lowering down folds value will not be helpful to find the most performing model and taking a higher value will take a longer time to completely train the model.
So, you need to find a spot where the cost and performance tradeoff gets to an equilibrium state. This can be done during hyper tuning analysis.
Finally, the most important thing is the size of your data. If the amount of data is small, using a k-fold cross-validation scheme would not make any sense. And if the amount of data is large, you must give efforts to choose the perfect value of K.
Types of Cross Validation
There are several variants of k fold cross-validation, used for different purposes. Many variants are implemented in the Scikit-Learn library. Some of the most widely used cross-validation techniques are-
- Repeated K fold Here the k-folds repeats itself n times. If you need to run KFold n times, you can implement this class from sklearn library. It will produce different splits in each repetition.
- Leave One Out Cross Validation(LOOCV) It is a simple cross-validation technique. Each training set contains all the samples except one. This one sample is used taken to the test set. Thus, we have different training sets and test sets for samples. It is a good choice for small data sets. This technique ensures more variance in the test set and lowers bias in the model.
- Shuffle and Split Like the k fold cross-validation, where a user defines a value of k for the number of folds. The process first shuffles the samples and then splits them into a pair of training and test set for each fold. The user can control the randomness for reproducibility.
- Stratified K Fold It is a variation of k fold that returns stratified folds. Here the 'stratified' represents the preservation of the percentage of samples for each class. Each fold contains approximately the same percentage of samples of each target class as the complete set. This method ensures the exact or as close as possible distribution of classes across all the folds.
- Time Series Split It is a special variation of k fold cross-validation to validate time series data samples, observed at fixed time intervals. It returns first k folds as train set and the (k+1) th set as test set. Unlike conventional k fold cross-validation methods, successive training sets are supersets of those that come before them. It also adds all surplus data to the first training set that is always used to train the model.
Advantages and Disadvantages of K fold Cross
There are some advantages of k fold cross-validation with over validation techniques. There are some disadvantages as well. Let's have a look at them.
Advantages
- Better Model Accuracy Using k-fold cross validation you will get a more accurate model than using just a random split of data set into train and test sets.
- Reduce Overfitting When you are using cross-validation, the model is rigorously trained and tested along the way. So, the data you give to the model will be distributed in a more proper way than just a train and test method. This will make the model less overfitted to the train set, eventually giving an improved performance on unseen data.
- Better Hyperparameter Tuning Hyperparameter tuning methods such as grid search and random search with k fold cross-validation are more powerful than without cross-validation. You should use hyperparameter tuning methods with cross-validation for better performance.
- Better Feature Extraction Cross-validation can be used to extract the most important features of a data set. Reverse Feature Extraction with Cross-Validation(RFECV) is a method that uses cross-validation while extracting the best features for a machine learning model.
- Improved Models for Imbalanced Data K fold cross-validation methods are very handy for imbalanced data. As the data is equally split among the train and test sets, the distribution of the data will be balanced, eventually leading to a better performing model.
Disadvantages
- Computational Cost Doing cross-validation will require extra time. If you choose cross-validation methods like LOOCV for large data samples, the computational overhead will be high. But using like 5 fold or 10 fold cross-validation would not take much time. And the performance will be quite satisfactory.
- Bad with Sequential Data If you are working with sequential data such as time-series data, k fold cross-validation is a bad choice. Because it does not work well with sequential data due to its nature. In time series, you need to predict the future value based on a series of past values of your data. Under this constraint, k fold will be failed to perform well. But you can use the time-series split, a variation of k fold, to cross-validate the time series model.
Comparison with Other Validation Method
There is a continuous debate on which method of validation is best for a model. Most of the time it is k fold. Let's compare k fold with other validation methods.
Holdout Vs. K fold Cross-Validation
In the holdout method, we split the data set into train and test sets. The model is trained on the train set and then evaluated by the test set. The method is simple and easy to implement. But not a better indicator of the performance of your model. As cross-validation uses multiple splits for train and test sets, it gives you a better indication of the performance of your model on unseen data.
The holdout method comes in handy when you are using a large data set or you are in short of time as cross-validation incurs more computational cost. But yet you should apply cross-validation whenever possible instead of the holdout method.
K fold Cross Validation Vs. Bootstrap
In the bootstrapping method, the data set is resampled at random to make several data sets so that the model can be evaluated with a wide number of data samples. The method samples the original data and takes the 'not chosen' samples as test cases. Then the average accuracy score is taken as the estimation of the model performance.
In essence, the bootstrap method can be seen more as a variance/bias estimation rather than a validation technique. It is useful in ensemble methods such as a random forest as it can create multiple data sets from the original data. We can use each bootstrap data set for building a number of single models (e.g. a decision tree) and combine all models with an ensemble model. Then we will take the majority voting of all these single models to get our final model performance.
On the other hand, k fold cross-validation splits the original data set to rigorously train and test the model.
In this sense, we can see that bootstrapping is not the right kind of evaluation model like k fold cross-validation. We still need k fold to evaluate the model's performance. The bootstrap method will be a weaker evaluation technique if used alone.
Final Words
In this tutorial, I tried to explain all the important aspects of k fold cross-validation. In summary, the key take ways of the tutorial are-
- What is k fold cross-validation and why it is necessary for model evaluation
- Implementation in Python
- Advantages and disadvantages of cross-validation
- Comparison of k fold cross-validation with other validation methods
Hope the tutorial has served you the concepts well. Do you have any questions about the concepts of the tutorial? Please let me know in the comments. You can also give feedback to improve the tutorial. I will gladly accept any new idea to make things better.
Happy Machine Learning!