- Introduction to Deep Learning
- Data Preprocessing for Deep Learning
- Convolutional Neural Networks
- Recurrent Neural Networks (RNNs)
- Long Short Term Memory (LSTM) Networks
- Transformers
- Generative Adversarial Networks
- Autoencoder
- Variational Autoencoders
- Diffusion Architecture
- Reinforcement Learning in Deep Learning
- Optimization Algorithms for Deep Learning
- Regularization Techniques
- Model Tracking and Accuracy Analysis
- Hyperparameter Tuning Techniques
- Transfer Learning
- Deployment of Deep Learning Models with REST API
- Deep Learning on Cloud Platforms
- Mathematical Foundations for Deep Learning
Transformers | Deep Learning
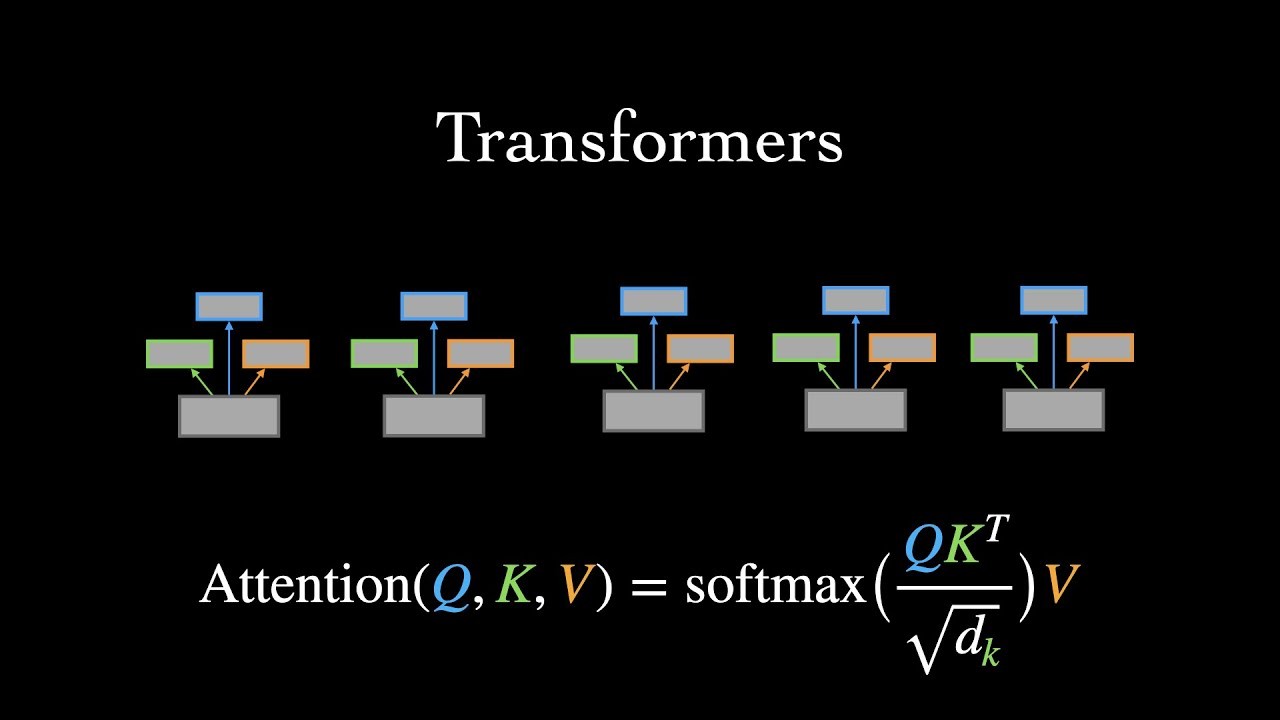
Simply put, transformers are a type of neural network that operates by learning context in sequential data. It uses the concept of self-attention to achieve this. Because of this, transformers are able to provide a wider range of contextual information in a given input sequence. This in turn improves the performance of natural language processing tasks like speech recognition or machine translation. It also performs well for machine learning tasks involving time series data such as stock prediction. With the advent of transformers, learning is no longer done word by word but by providing attention to all the words to provide direction for learning. Transformers are now the most common efficient model for completing various tasks in Deep Learning and NLP.
The concept of transformers was introduced in 2017 in a paper titled Attention is All you need.
The Architecture of Transformers
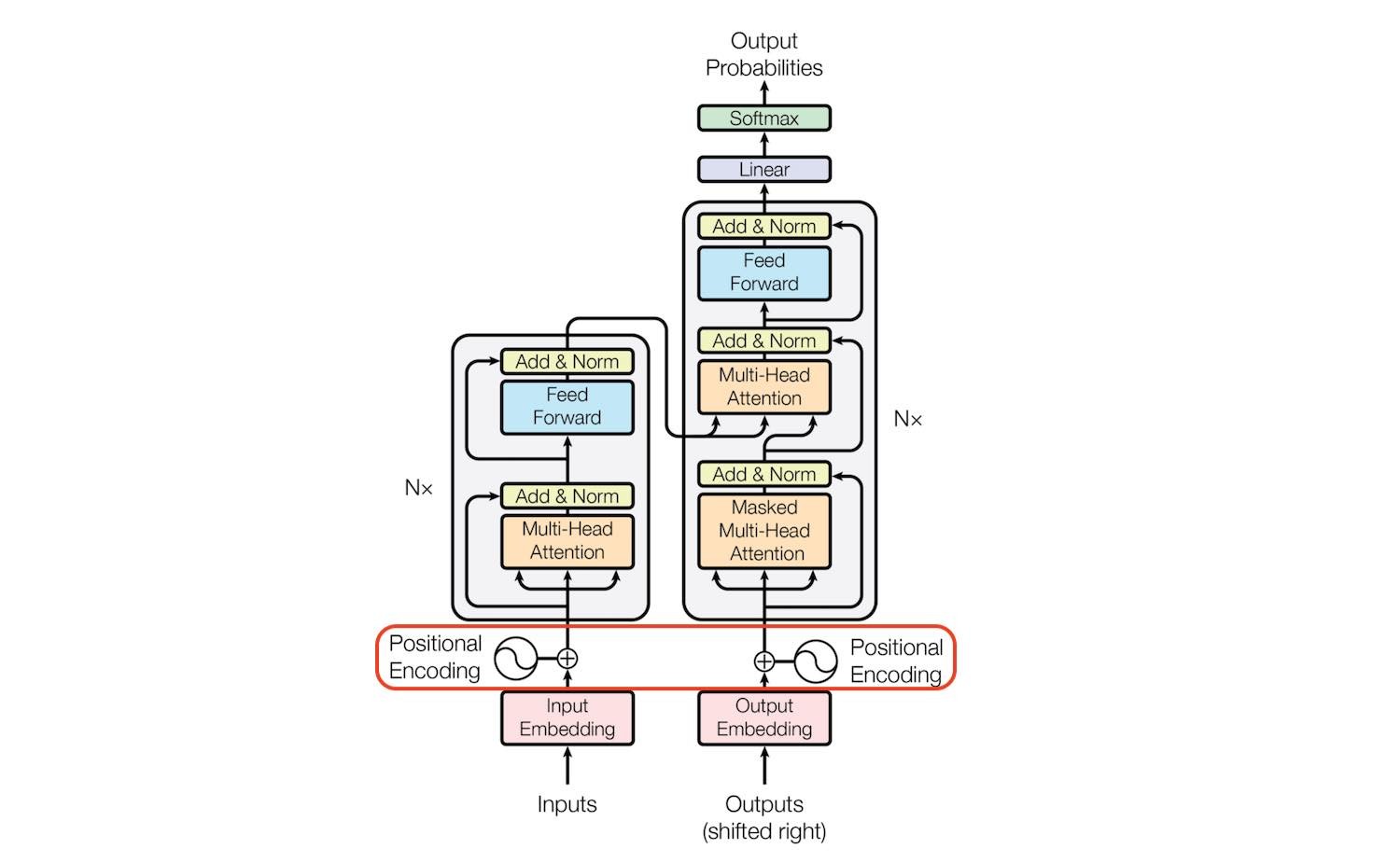
The architecture that the transformer model follows is the encoder-decoder architecture.
To understand the transformer model we first need to be introduced to some key concepts that transformers use:
Self Attention
According to the 2017 paper attention is all you need, self-attention is described as follows:
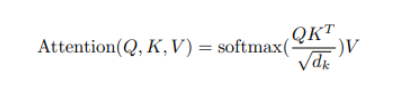
“Self-attention, sometimes called intra-attention, is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence.”
It is the most important component of the transformer architecture. Self-attention works by comparing all input sequences with each other. In addition to this, it modifies the positions of the corresponding output positions.
Self-attention consists of a few components:
Query
Key
Values
The input X is a sequence of embedding. Its length is L and its dimension is d.
Initially, X is projected into 3 matrices:
Query: XQ=WQX
Key: XK=WKX
Value: XV=WVX
All of these three matrices have the same shape as X
Next, we construct the equation representing the “soft sequence-wise nearest neighbor search”.
All combinations of XK and XQ are searched
For each sequence position, the more X0K is similar to X0Q the greater the value of X0V
The equation boils down to Y=softmax(QKt)V
In transformers, before softmax is applied, the result is scaled by dividing the result by the square root of the query size. This is known as scaled dot product attention.
The overall equation can now be described as
These results are added to the residual connection. Then the output is normalized.
Essentially, self-attention works by mapping between a set of key-value pairs and a query to an output.
Multi-head attention
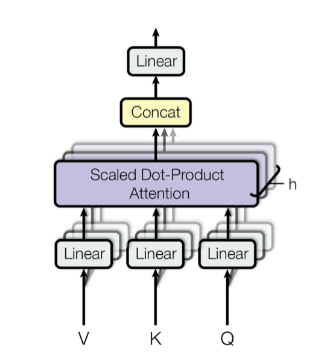
Transformer architecture uses a more complex version of self-attention layer called the Multi-head self-attention. This mechanism is as follows:
Linear transformation is performed on Query Key and Values Q, K, and V.
Attention is then performed a specific number of times. The number of heads determines this number.
In this way, each multi-head attention focuses on a different subspace. Each sub-space would have a different syntactic or semantic meaning.
With multi-head attention, the equation becomes:

The overall equation becomes:
Here, WQWKWV represents learned parameters.
Positional Encoding:
Transformers do not rely on sequential processing like RNNs. Instead, it uses positional encoding to add positional information in order to maintain the sequential nature.
Positional encoding represents the location of an entity in a sequence. In this way, each position is assigned a unique representation.
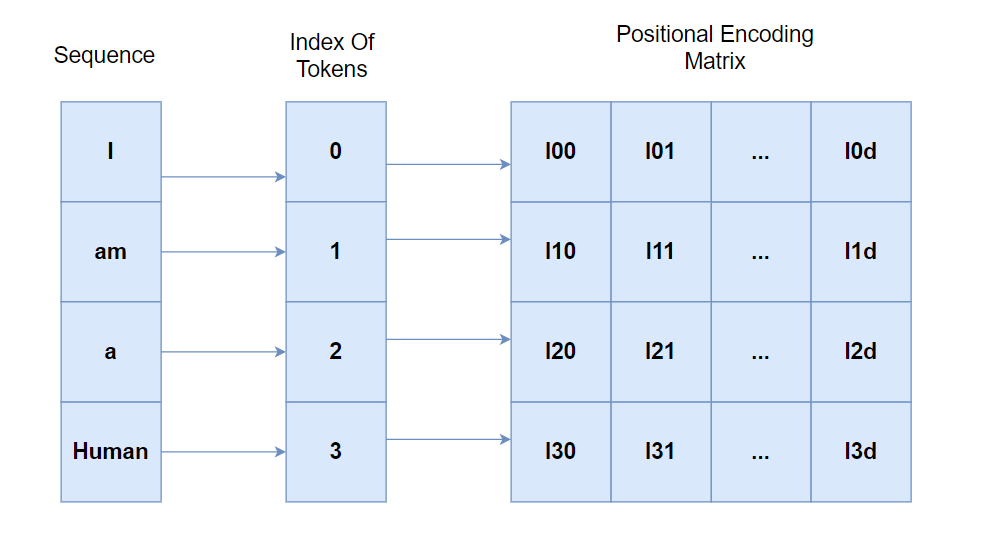
In the transformer encoding scheme, each location is mapped to a vector as we can observe in the diagram above.
The resultant output of positional encoding is a matrix where each row represents the encoded object of the sequence.
The formula for positional encoding is:
PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
Here,
i = index of encoding dimension
d_model = dimensionality of the input embedding
pos = postion of the object in the input sequence.
Encoder-Decoder Architecture
Simply put encoder-decoder architecture consists of two components: an encoder network and a decoder network. The encoder network is responsible for taking an input sequence and generating a mixed-length representation of that sequence. The decoder network is responsible for taking this representation and generating an output sequence one step at a time.
Encoder Network: the encoder network consists of a stack of N identical layers that process the input sequence. Each of these layers consists of two sublayers:
Multi-head self-attention layer
Fully connected feed-forward network layer position-wise
Each layer passes the output to the next layer
Decoder layer: output is generated one sequence at a time. It has N layers identical to the encoder network. Each layer has three sublayers:
Masked multi-head self-attention layer-responsible for allowing models to attend to only previous output tokens
Multi-head attention layer over the encoder output
Fully connected position-wise feed-forward network.
After the decoder network final layer output is passed through a linear transformation followed by a softmax activation function.
Transformers show state-of-the-art performance in various sequence-to-sequence learning tasks such as in text generation and machine learning translation.
Use cases of Transformers
Text classification
Machine translation
Question-answering tasks
And many more sequences to sequence learning tasks.
Implementation of Transformers
In this tutorial, we will be using the transformer model for text classification purposes.
The dataset we are using for this tutorial is the IMDB dataset. You can download the dataset from keras datasets. The objective of the model is to predict whether the reviews for a movie are positive or negative. We will be using Tensorflow and Keras libraries for model construction and for training.
First, we import the libraries required. You will get the full code in Google Colab also.
# Import TensorFlow and Keras libraries. import tensorflow as tf from tensorflow import keras # It is a popular dataset for binary sentiment classification tasks. # This dataset is already preprocessed and tokenized, making it convenient for learning and practicing deep learning techniques. from tensorflow.keras.datasets import imdb
The imports include modules that transformers need, like MultiHeadAttention, Embedding, and GlobalAveragePooling along with additional components like layer normalization responsible for standardizing data, dense layer, and dropout which is required for regularization.
# Import necessary classes and functions from TensorFlow Keras. from tensorflow.keras.models import Sequential, Model from tensorflow.keras.layers import MultiHeadAttention, LayerNormalization, Dropout, Layer from tensorflow.keras.layers import Embedding, Input, GlobalAveragePooling1D, Dense # Import the NumPy library for numerical operations and array handling. import numpy as np # Import the 'warnings' module to handle warning messages. import warnings # Filter out visible deprecation warnings from NumPy to avoid clutter in the output. warnings.filterwarnings("ignore", category=np.VisibleDeprecationWarning)
# Import necessary classes and functions from TensorFlow Keras. from tensorflow.keras.models import Sequential, Model from tensorflow.keras.layers import MultiHeadAttention, LayerNormalization, Dropout, Layer from tensorflow.keras.layers import Embedding, Input, GlobalAveragePooling1D, Dense class Transformer(Layer): def __init__(self, embed_dim, num_heads, ff_dim, rate=0.1): # Call the constructor of the parent class (Layer) to initialize the layer. super(Transformer, self).__init__() # Multi-Head Attention layer self.attention = MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim) # Feed-Forward Neural Network for each token # The 'Sequential' class allows defining a sequence of layers in Keras. self.feed_forward_network = Sequential( [Dense(ff_dim, activation="relu"), Dense(embed_dim),] ) # Layer normalization for attention output self.norm1 = LayerNormalization(epsilon=1e-6) # Layer normalization for feed-forward network output self.norm2 = LayerNormalization(epsilon=1e-6) # Dropout layers to regularize the model self.dropout1 = Dropout(rate) self.dropout2 = Dropout(rate) def build(self, input_shape): """ This method is called when the layer is built, and it is used to define any additional operations or configurations specific to the Transformer layer. It overrides the build() method from the parent class. Parameters: input_shape (tensor): The shape of the input tensor. Returns: None """ super(Transformer, self).build(input_shape) # Additional build operations if needed def call(self, inputs, training): """ This method defines the forward pass of the Transformer layer, applying the attention mechanism and feed-forward network to the input tensor. Parameters: inputs (tensor): The input tensor to the Transformer layer. training (bool): A boolean flag indicating whether the layer is in training mode or inference mode. Returns: tensor: The output tensor of the Transformer layer. """ attention_output = self.attention(inputs, inputs) attention_output = self.dropout1(attention_output, training=training) output1 = self.norm1(inputs + attention_output) feed_forward_network_output = self.feed_forward_network(output1) feed_forward_network_output = self.dropout2(feed_forward_network_output, training=training) return self.norm2(output1 + feed_forward_network_output)
Next, we construct the transformer block model:
In the transformer layer, the self.attention contains the MultiHeadAttention layer where the number of heads and the embedded dimension are entered as arguments. The activation layer for the feed-forward network is Relu. The input is added with the attention output to construct the output which is then fed to the feed-forward network. The call function returns the feed-forward network output added to the original output.
class TokenAndPositionEmbedding(Layer): # Define a custom layer for token and position embedding. def build(self, input_shape): # Define the build method for the custom layer. super(TokenAndPositionEmbedding, self).build(input_shape) # Call the parent class's build method. # Additional build operations if needed # Optional: Add any additional operations during build. def __init__(self, maximum_length, vocabulary_size, embed_dim): # Initialize the custom layer with parameters. super(TokenAndPositionEmbedding, self).__init__() # Call the parent class's constructor. self.token_embedding = Embedding(input_dim=vocabulary_size, output_dim=embed_dim) # Create a token embedding layer. self.pos_emb = Embedding(input_dim=maximum_length, output_dim=embed_dim) # Create a positional embedding layer. def call(self, x): # Define the forward pass for the custom layer. maximum_length = tf.shape(x)[-1] # Get the maximum sequence length of the input. positions = tf.range(start=0, limit=maximum_length, delta=1) # Generate positional indices. positions = self.pos_emb(positions) # Get positional embeddings. x = self.token_embedding(x) # Get token embeddings for the input. return x + positions # Add token and positional embeddings element-wise.
Next, we construct the token and positional embedding model:
In this model we use the embedding function imported from tensorflow.keras to perform positional embedding on input. The resultant positions are added with the tokenized embeddings and the combined output is returned.
vocabulary_size = 20000 # Amount of words considered maximum_length = 200 # Size of each movie review (x_train, y_train), (x_val, y_val) = imdb.load_data(num_words=vocabulary_size) x_train = tf.keras.preprocessing.sequence.pad_sequences(x_train, maxlen=maximum_length) x_val = tf.keras.preprocessing.sequence.pad_sequences(x_val, maxlen=maximum_length) #adding padding sequence embed_dimension = 32 # Size of token embeddings num_heads = 2 # Number of attention heads feedforward_dimension = 32 # Feed forward network hidden layer size
We define the hyperparameters:
First, the embedded size for each token, the number of heads, and the number of hidden layers residing in the feed-forward network are defined. The vocabulary size determines how many words will be considered from the dataset. In this case, it is the top 20K words. The maximum length determines how many words will be considered for each movie review.
Preprocessing
After the data is loaded padding sequence is added for the training and validation input data.
# Import required libraries from tensorflow.keras.layers import Reshape # Define the input layer with a given maximum sequence length inputs = Input(shape=(maximum_length,)) # Create a TokenAndPositionEmbedding layer with specified parameters embedding_layer = TokenAndPositionEmbedding(maximum_length, vocabulary_size, embed_dimension) # Apply the TokenAndPositionEmbedding layer to the input data x = embedding_layer(inputs) # Create a Transformer block with specified parameters transformer_block = Transformer(embed_dimension, num_heads, feedforward_dimension) # Apply the Transformer block to the token and positional embeddings x = transformer_block(x) # Reshape the output from 2D tensor to 3D tensor (batch size of 1 is added) x = tf.expand_dims(x, axis=0) # Apply Global Average Pooling along the temporal dimension x = GlobalAveragePooling1D()(x) # Apply dropout regularization to prevent overfitting x = Dropout(0.1)(x) # Apply a dense layer with ReLU activation x = Dense(20, activation="relu")(x) # Apply dropout regularization again x = Dropout(0.1)(x) # Apply the final dense layer with softmax activation for binary classification outputs = Dense(2, activation="softmax")(x) # Create the Keras Model object with defined inputs and outputs model = Model(inputs=inputs, outputs=outputs) # Call the TokenAndPositionEmbedding and Transformer layers to create their weights for layer in model.layers: if isinstance(layer, TokenAndPositionEmbedding) or isinstance(layer, Transformer): layer.build(layer.input_shape)
We then construct the overall model which uses the two models mentioned above.
The model structure is then defined as follows:
First, the positional embedding will take place on the inputs in the embedding layer.
Next, the output will be passed to the Transformer block.
Finally, the output is passed through dense layers with dropout layers added for regularization purposes.
The final activation function used for this case is the softmax activation function.
# Compile the model with the Adam optimizer, sparse categorical cross-entropy loss, and accuracy metric model.compile(optimizer="adam", loss="sparse_categorical_crossentropy", metrics=["accuracy"]) # Train the model using the training data (x_train, y_train) and validate it on the validation data (x_val, y_val) # The training will run for 2 epochs with a batch size of 64 samples per batch history = model.fit(x_train, y_train, batch_size=64, epochs=2, validation_data=(x_val, y_val)) # Evaluate the trained model on the validation data (x_val, y_val) results = model.evaluate(x_val, y_val, verbose=2) # Print the evaluation results (loss and accuracy) for the validation data for name, value in zip(model.metrics_names, results): print("%s: %.3f" % (name, value))Model Training
The optimizer that is used for model training is the adam optimizer and the loss used here is the sparse categorical cross-entropy loss.
The model is trained for two epochs with validation data added.
The output of the accuracy is:

Best Practices for Optimizing the Performance of Transformer Models
Avoid overfitting- To allow the model to learn instead of memorizing training data, techniques can be used like regularization and early stopping. In the example above we use dropout to avoid overfitting.
Using an appropriate batch size- It is incredibly important for using the proper batch size. If the batch size is too small, learning may be too slow and if it’s too high, it can cause memory issues. Finding balance is crucial to the overall performance of the model.
In the example above the batch size used was 64.
Using the appropriate evaluation metric- It depends on the application. For example, for sentiment analysis evaluation metric such as F1 score or accuracy is appropriate, whereas for machine translation BLEU (Bilingual Evaluation Understudy) is a common evaluation metric,
Applications of Transformers in Engineering
They have mainly been used for natural language processing(NLP) tasks. In addition to this, they are also used in computer vision tasks.
Some applications where transformers made improvements:
ChatBots: Transformer-based models such as GPT3 have achieved remarkable progress in chatbot applications than their predecessors. It allows for more contextually important and human-like experiences in chatbots.
Sentiment analysis: By offering a more nuanced analysis of text data, transformer models capture more complex patterns and relationships between words and sentences compared to previous methods that relied on simple rule-based approaches or bag-of-words models.
Recommendation Systems: Transformers have allowed for more personalized and accurate recommendation systems as they have been able to identify patterns between users and products along with their similarities.
Some of the best transformer-based models include:
BERT- developed by Google it is popular for its use in general question and answering. RoBERTa is another model which is part of the BERT family, which is used for the same application.
BART- whose encoder is BERT and decoder is GPT. It is popular for its use in text generation and understanding. BART was developed by Meta.
Future of Transformers in Deep Learning Engineering
With the recent advances in the transformer era for example the GPT 3 or BART, The potential implications for the use of transformers in both the NLP and Computer Vision sectors seems potentially endless. However, the use of transformers is computationally expensive due to their large number of parameters and their self-attention mechanisms. Hence this limits their use case for low-end devices and also restricts their work with large datasets.
In this article, we have covered the concepts of how a transformer works, from the key concepts used by transformers in deep learning, which included self-attention, and multi-head attention to the encoder-decoder architecture. Next, we have implemented a transformer model to train on the IMDB dataset using Keras and TensorFlow. Finally, we talked about some of the best practices for optimizing the performance of transformer models and the applications of transformer models.