- Introduction to Deep Learning
- Data Preprocessing for Deep Learning
- Convolutional Neural Networks
- Recurrent Neural Networks (RNNs)
- Long Short Term Memory (LSTM) Networks
- Transformers
- Generative Adversarial Networks
- Autoencoder
- Variational Autoencoders
- Diffusion Architecture
- Reinforcement Learning in Deep Learning
- Optimization Algorithms for Deep Learning
- Regularization Techniques
- Model Tracking and Accuracy Analysis
- Hyperparameter Tuning Techniques
- Transfer Learning
- Deployment of Deep Learning Models with REST API
- Deep Learning on Cloud Platforms
- Mathematical Foundations for Deep Learning
Introduction to Deep Learning | Deep Learning
Have you ever imagined a car driving without a human? A machine will translate any language for you. A machine will diagnose your disease and many other domains that are possible because of deep learning and artificial intelligence. It makes our life easier than before. Let’s explore deep learning.
This tutorial is divided into five subtopics to give you a full overview of deep learning. Before jumping into the topics, let’s know the topic’s name.
Introduction
Fundamentals of deep learning
Advanced deep learning techniques
Deep learning applications
Conclusion
Introduction to Deep learning
What is Deep learning?
Deep learning is a subfield of machine learning that involves using neural networks to recognize patterns and make predictions on large amounts of data. It’s a way to enable machines to learn from data and improve performance on specific tasks without being explicitly programmed. It uses multiple layers of neural networks to perform complex tasks. It has the ability to automatically identify the non-linear relationships between inputs and outputs of data. It can extract meaningful information from raw data like images, text, voice, and other unstructured data.
Another benefit of deep learning is feature engineering or feature learning. If we want to teach a machine through traditional machine learning and deep learning algorithms, then it is needed to perform feature engineering to extract meaningful information from data and structure the data before training. It becomes complex when unstructured data (text, images, etc.) comes. But in deep learning, there’s no need to perform feature engineering. The deep learning models automatically perform the feature extraction part from data and even in complex data.
Deep Learning History
The stage of today’s deep learning doesn’t come in a day. It comes over a long time. At first, In 1943, Warren McCulloch and Walter Pitts proposed the first mathematical model of an artificial neuron. Then in 1958, Frank Rosenblatt proposed a single-layer perceptron capable of binary classification. In 1969, the limitations of single-layer perceptron were discovered by Marvin Minsky and Seymour Papert.
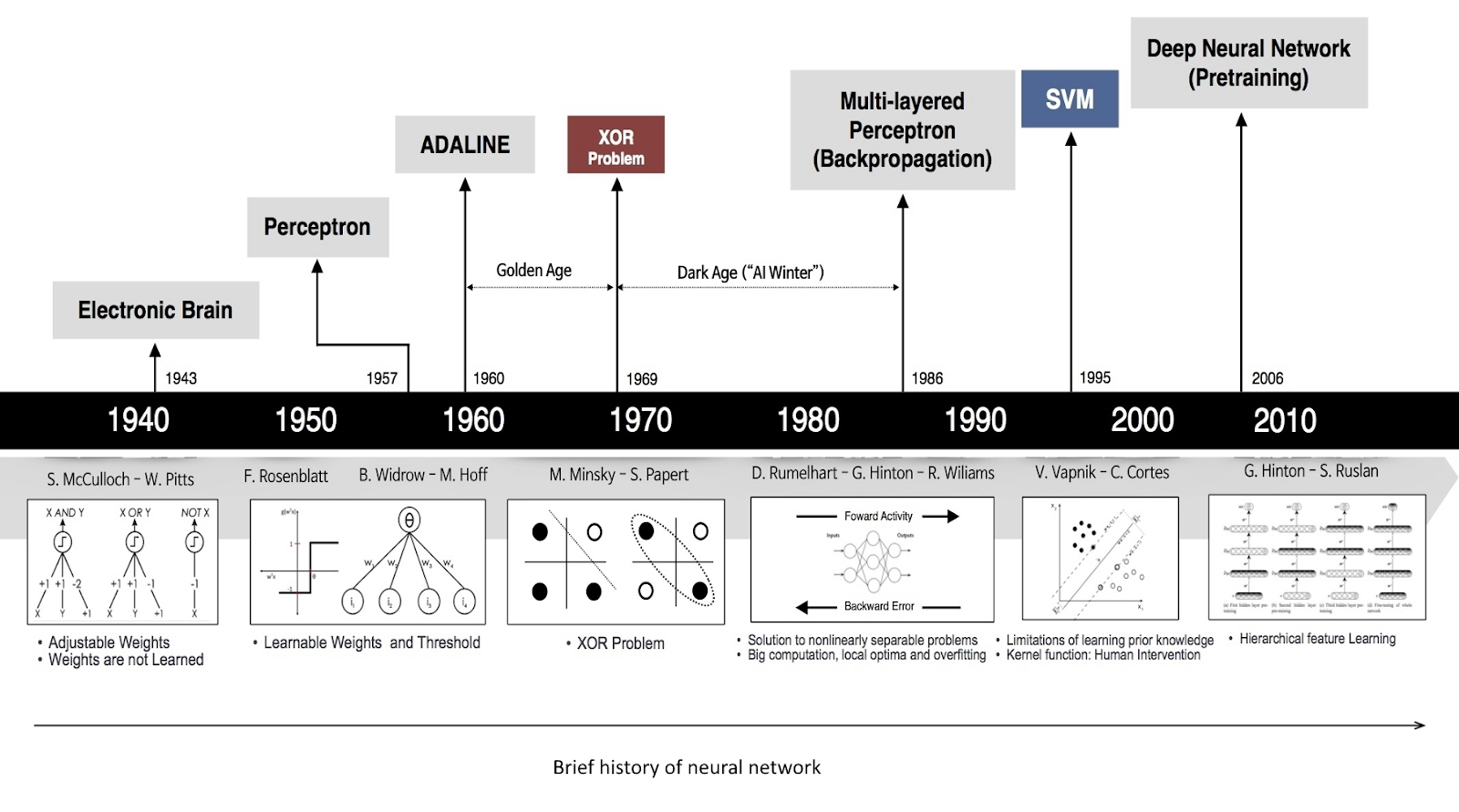
After some years, in 1986, the backpropagation deep learning algorithm was discovered by Geoffrey Hinton, David Rumelhalt, and Ronald Williams. That was a master invention in the deep learning field. Then in the Early 2000s, The Convolutional Neural Networks(CNN) was developed by Yann LeCun. Then, in 2006, Geoffrey Hinton introduced the deep belief networks. Then in 2012, the AlexNet model played a significant role in Computer Vision tasks. In 2014, Generative Adversarial Networks(GANs), Recurrent Neural Networks(RNN), and Long Short-Term Memory(LSTM) were introduced which make deep learning more powerful in many tasks. In 2018, OpenAI introduced the GPT-2 transformer model that achieves state-of-the-art Natural Language Processing(NLP) understanding and generating tasks. Research in deep learning is going on. The algorithms and techniques of deep learning are developing over time. Today, the growth of deep learning algorithms and applications is exponential. This is how deep learning history was created.
Importance of Deep Learning in Modern Technology
Many researchers think that after some years, Artificial Intelligence will replace a lot of human manual tasks by doing them automatically. Let’s know in which fields deep learning is used in modern technology, given below:
Computer Vision: Today we can accurately classify images, detect objects from images or videos, segment a particular part of the images or videos, analyze the video, and so on by deep earning. So, many applications are achieved, such as autonomous vehicles, security systems, medical imaging, Augmented Reality, and so on.
Natural language Processing (NLP): Many NLP tasks such as question answering, sentiment analysis, and machine translations can be developed today. So, many Deep Learning applications like chatbots, virtual assistance, advanced search engines, and more have been created today.
Speech Recognition & Synthesis: Now we can easily do speech-to-text conversion, text-to-speech synthesis, transcription services, accessibility tools, and so on.
Recommendation Systems: By analyzing customers' behavior, we can provide personalized recommendations for online shopping, media streaming, content discovery, and so on through deep learning.
Gaming: Today machines can learn complex games and defeat humans such as AlphaGo where AI defeated a world champion Go player.
HealthCare: deep learning is a revolutionary in healthcare. Through deep learning, we can detect diseases early, discover new drugs, and suggest many things about health.
Fraud detection and Cybersecurity: We can detect suspicious activities, detect anomalies, predict potential threats in financial transactions, and network security through deep learning.
Robotics: Deep learning helps robots to learn complex patterns from their environment, adapt to new situations, and perform tasks more effectively.
There are many other applications where deep learning is important in modern technology. Overall, deep learning is used in diverse areas of modern technology. As the days go on, research is increasing, and new exciting fields are coming.
Fundamentals of Deep Learning
Neural Networks
A neural network is designed by the structure and function of the human brain. In the human brain, A biological neuron consists of 3 parts: Dendrites, Cell body (soma), and Axon. Dendrites receive signals from the end of another neuron. Then Cell Body processes the signals and makes the decision about where to transmit the signal. And Axon takes the neuron's output and transmits it to another neuron.
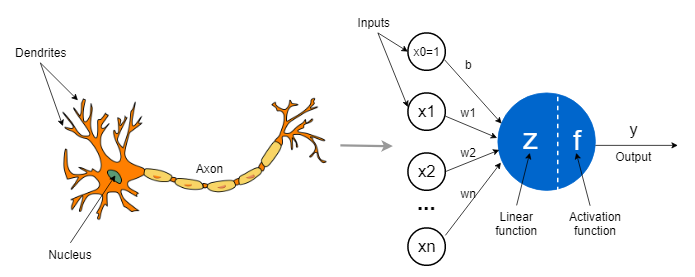
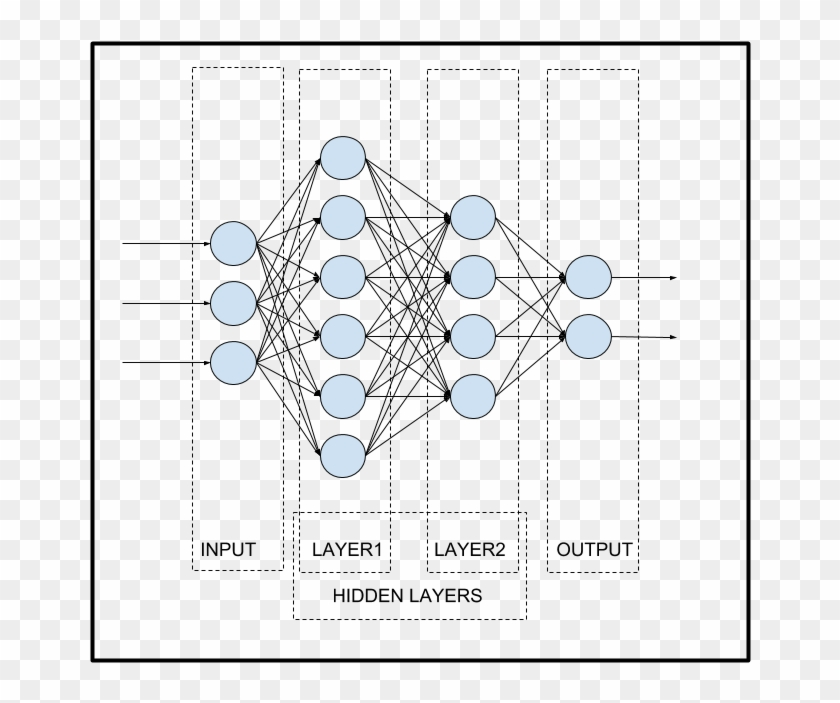
Like the biological Neuron, the Artificial Neuron does the same thing. It takes input data, processes the data, and provides the output to another neuron. A neural network consists of interconnected artificial neurons or nodes that are organized in layers. There are three basic layers in Neural Networks. Including:
Input Layer: The first neural network layer takes in the unprocessed input data. Each neuron represents a characteristic or property of the input data in the input layer.
Hidden layers: Between the input and output layers, there exist hidden layers. They are called "hidden" because their activations are internal representations of the input data and cannot be seen externally.
Output layer: The neural network's output layer is the topmost layer. It generates the predictions or outputs of the network based on the calculations made in the hidden layers. The type of task will determine how many neurons are in the output layer. For instance, a single neuron in the output layer may generate a probability score between 0 and 1 in a binary classification issue.
Types of Neural Network
There are a lot of neural networks designed for various tasks. Some of them are given below.
Feedforward Neural Network (FNN): It is the simplest neural network where information flows only in one direction from input to output and is generally used for classification and regression.
Convolution Neural Network(CNN): It is designed for grid data processing, like images. It has the ability to learn hierarchical representations of the input data and make predictions. Widely used in Computer vision tasks.
Recurrent Neural Network(RNN): It is designed for handling sequential data like text, time series data, speech, and so on.
Long Short-Term Memory(LSTM): A variation of RNN that solve the vanishing gradient problem and enables the model to learn long-term dependencies from data.
Gated Recurrent Unit (GRU): A simplified version of LSTM that solve the vanishing gradient problem. This model is more computationally efficient than LSTM.
AutoEncoder: It is designed for unsupervised learning where the encoder encodes the input data into latent space and reconstructs the latent space into original data as closely as possible. Autoencoders are used in Dimensionality reduction, feature learning, and anomaly detection.
Generative Adversarial Networks(GANs): This model can generate new data samples that look realistic. It has two submodels: The generator model and the discriminator model. The generator model tries to generate realistic data, and the discriminator model tries to identify whether the given sample is fake or real. These two models train with adversarial processes. Image synthesis, style transfer, and image colorization are some applications of GANs.
Boltzmann Machines: It is a type of Unsupervised Deep Learning Algorithms that can be used to model complex probability distributions.
Transformer Neural Networks: This type of attention-based network uses self-attention mechanisms to process sequences of inputs. Language translation and text generation are the applications of Transformer Neural Networks.
There are a lot of neural networks for a variety of tasks. The research is going on and new algorithms are coming day by day.
Activation Function
An activation function is a mathematical function that is used to apply the weighted sum in the neuron to introduce the non-linearity into the network. Because of non-linearity, the model can learn complex patterns or relationships in the data. The activation function also helps to control the output range by different activation functions.
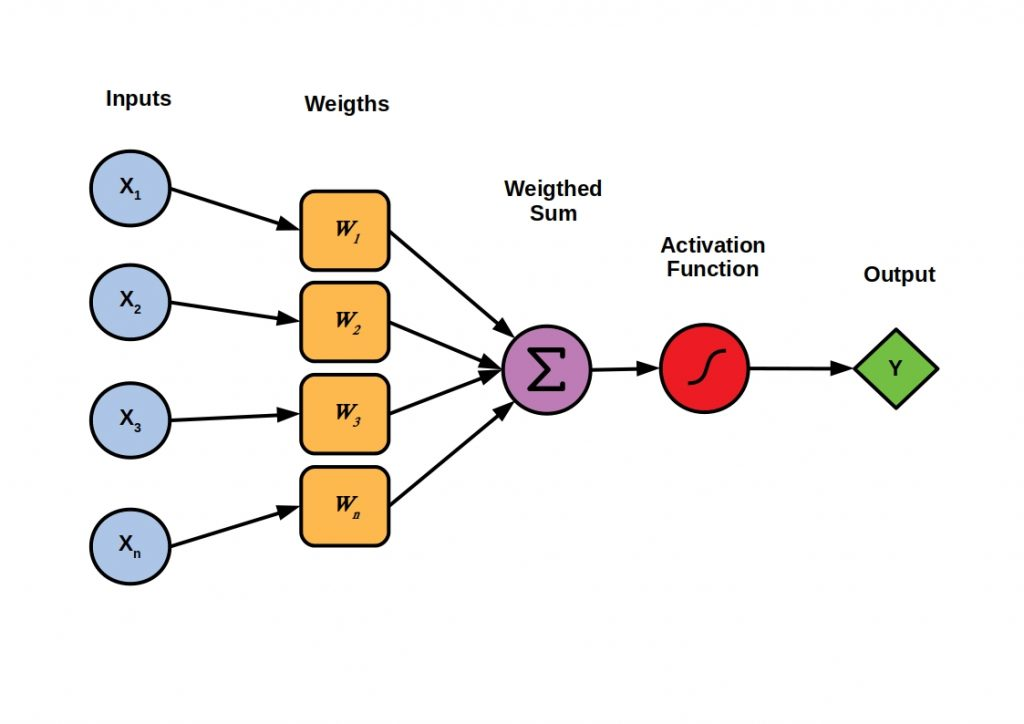
There are many activation functions, and each activation function has specific applications. Some popular activation functions are given below:
Sigmoid: An activation function utilized in deep learning and machine learning models is the sigmoid function. The input is translated to a value between 0 and 1 using a distinctive S-shaped curve. The mathematical formula for the sigmoid function is (x) = 1 / (1 + exp(-x)).
The exponential function, exp(), raises the value of the mathematical constant 'e' (about 2.71828) to the power of the input. Where (x) is the output value (also known as the activation) of the sigmoid function for the input 'x'.
- Tanh: Another well-liked non-linear activation function in artificial neural networks is the tanh (hyperbolic tangent) activation function. It is an extension of the sigmoid function, and unlike the sigmoid's output, which is centered around 0, its output spans the range of -1 to 1, giving a zero-centered activation. Mathematical definition of the Tanh function:f(x) = (2 / (1 + exp(-2x))) - 1
Where f(x) is the output (activation) of the tanh function for the input 'x.' and exp() is the exponential function, which raises the mathematical constant 'e' (approximately 2.71828) to the power of the input.
Relu: One of the most popular activation functions in deep learning and artificial neural networks is the ReLU (Rectified Linear Unit). It brings non-linearity to the network, enabling it to recognize and interpret complicated patterns in the data. It is a straightforward yet effective non-linear activation function.
The ReLU function is defined as follows:f(x) = max(0, x)where f(x) is the output (activation) of the ReLU function for the input x and max(a, b) returns the larger value between 'a' and 'b.'
Leaky Relu: It’s a variant of Relu that solves the ‘dying Relu’ problem. The formula is f(x) = max(alpah*x,x) where alpha is a very small positive constant such as 0.001,0.01,0.0001, and so on.
ELU: Exponential Linear Unit (elu) activation function is almost similar to Relu, which is smooth & differentiable everywhere. It also solves the dying Relu problem.
Softmax: This activation function is used in multiclass classification problems. It is used to classify the input into one of several possible classes. The class with the highest probabilities can be chosen as the targeted output.
Swish: It is a recent addition member of the activation family. The formula is f(x) = x * sigmoid(x). It combines the benefit of linear and sigmoid activation functions.
Many other activation functions exist that have been used in specific domains. Here, you just get a brief idea of the activation function.
Backpropagation Algorithm
It is an essential algorithm for training deep learning models. To understand the backpropagation algorithm, it is needed to understand the training process.
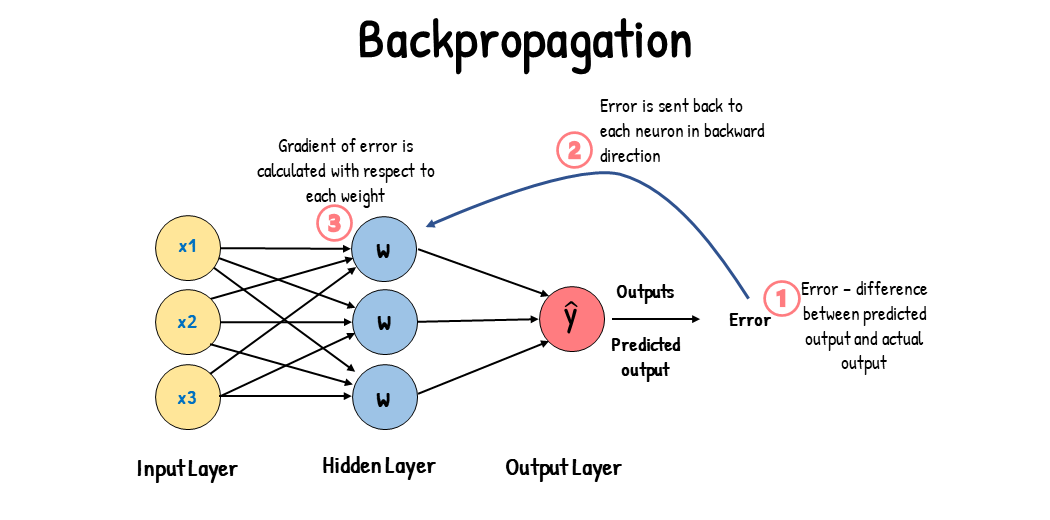
The step-by-step is given below.
Forward Pass: The whole network takes the input and produces the output.
Compute Loss: The loss function computes the difference between the predicted output & actual output. The goal is to minimize the loss.
Backward Pass: The gradient of the loss function with respect to the weights and bias. This process starts from output layers and moves backward through the network using the chain rule of calculus.
Update the weights and biases: After calculating the gradients, the weights, and biases are updated in a learning rate that determines the step size of the update.
Here, Backward pass & update the weights and bias is the term of Backpropagation that can be told as an Optimization Technique. There are some popular optimization algorithms such as Gradient Descent, variants of Gradient Descent, Adam, Adadelta, and so on.
Training in Deep Learning
Before training the deep learning models, it is needed to know how to preprocess the input data, how the loss function works, What is optimization, and how to control the model with regularization. Let’s understand those concepts briefly.
Data Preprocessing
It is a very important part of deep learning. This step processes raw data for input into the model that can improve the model performance, speed up training, reduce the risk of overfitting, and so on. Some preprocessing technique have been briefly discussed below.
Data Normalisation: It is used to transform the data from different feature scales to the same scale which is more efficient for learning the model.
Data Augmentation: By applying the random transformations to the existing data, generate new data samples that increase the size of the training dataset and make the model more stable.
One Hot Encoding: It is used to convert categorical features into binary vectors.
Tokenization & embedding: Tokenization splits the text into words or subwords, where embedding maps these tokens into a continuous vector space so that the network can understand and process the text.
There are many other Data Preprocessing techniques that are used in specific areas in the deep learning field.
Loss Function
The loss function or cost function computes the difference between the predicted output of the neural network and actual output values. The goal is to minimize the loss during training. Some of the loss functions are given below
Mean Squared Error(MSE): It calculates the average squared difference between the predicted values and actual values.
Mean Absolute Error(MAE): it calculates the average absolute difference between the predicted values and actual values.
Cross Entropy loss: It measures the difference between predicted probability distribution & true probability distribution of the classes. Generally used in Classification tasks.
Binary Categorical Crossentropy: Especially it is used in binary Classification problems.
There are many others like Categorical Crossentropy, Hinge loss, Huber Loss, KL divergence loss, and triplet loss functions that are used in specific areas to help the deep learning models learnable.
Optimization Algorithms
Optimization algorithms are used to adjust the weights and biases of the neural network to minimize the loss functions. It computes the gradients of the neural network during backpropagation and updates the model parameters. The most common optimization algorithm is gradient descent and its variants. Some of them are discussed below
Stochastic Gradient Descent(SGD): It updates the model parameters using a randomly selected training example at each iteration.
Mini Batch Gradient Descent: It is the stage between Batch Gradient Descent and SGD that updates the model parameters using a small batch of training examples.
Adaptive methods: Many optimization techniques have been developed to adjust the learning rate for each parameter during training such as Adagrade, Adadelta, RMSprop, Adam, and so on.
Regularization Techniques
Deep learning models can learn from data and perform in three stages which are underfitting, perfect fitting, and Overfitting.
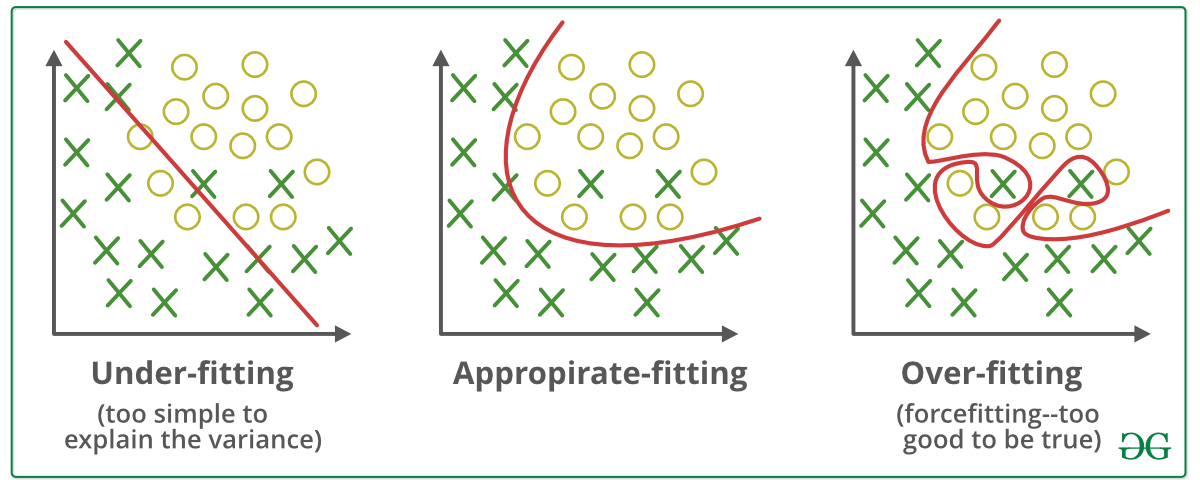
Underfitting happens when the model can’t learn well from the training dataset and can’t perform on the test dataset. Appropriate fitting means it gives a good performance in training datasets and testing datasets. Overfitting means the model gives a high performance in the training dataset but gives a poor performance in the test dataset.
To solve the under-fitting problem, some steps can be taken such as increasing the sample of the dataset, creating a more complex model, or increasing the parameters of the model, can use transfer learning models, and so on.
If Overfitting happens in the model, then regularization techniques need to be taken. Some of the regularization techniques are discussed below
L1 or L2 regularization: It is used to add a penalty term in the loss function based on the L1 or L2 norm.
Dropout: This technique randomly ‘drops out’ a fraction of neurons during training solves the overfitting problem and encourages the model to learn more robust features.
Early stopping: It means the training process will be stopped when the performance of a validation set starts to degrade.
Advance Deep Learning Techniques
Convolutional Neural Network
CNN is a special type of neural network that is used to analyze or predict grid-like data such as images, and videos. It has the ability to learn spatial hierarchies of features from data automatically. This model is useful in image classification, Object Detection, and Image Segmentation related tasks.
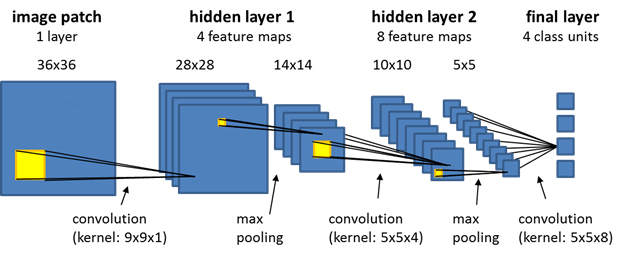
The CNN model consists of some layers. They are:
Input layer: It receives the input data such as image or video frames.
Convolutional Layers: These layers apply a series of convolution filters on the input image where each filter is responsible for learning the features or patterns in the data.
Activation functions: After the convolutional layer, the activation function is applied to the feature maps from convolutional filters. The activation functions such as Relu, Sigmoid, Tanh, etc are widely used.
Pooling layers: After the convolution operation, the Pooling layer is used to reduce the dimension of feature maps that decrease the computational complexity and the number of parameters in the network. MaxPooling and Average pooling are some popular pooling layers.
Fully Connected layers: After performing Convolution and pooling operations, the feature maps need to flatten and one or more fully connected layers are used to perform Classification or regression tasks.
Output layers: This layer gives the final prediction or classification.
Recurrent Neural Network
RNN is a type of deep learning algorithm that is used to handle sequential data like text, audio, time series data, and more. This model plays an important fact when the input data consist of order. Language modeling, Machine translation, Speech recognition, sentiment analysis, time series prediction, and video analysis are some applications of RNN.
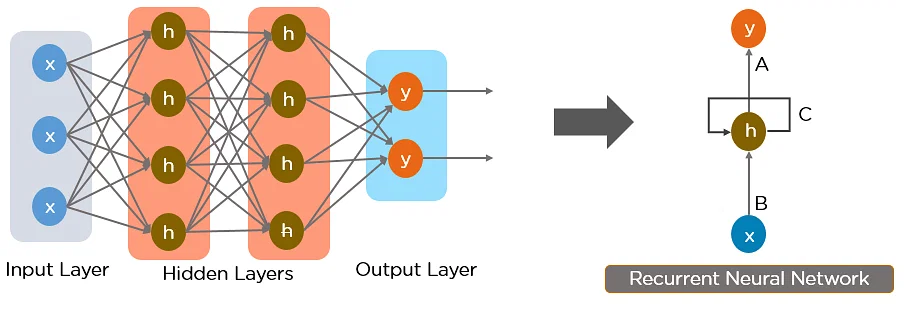
This model consists of some layers. A brief discussion of them is given below
Input layer: It takes the input from outside.
Recurrent hidden layer: This layer contains a recurrent unit that is responsible for maintaining and updating the hidden state. At each time step, the recurrent units take both the current unit and the hidden state from the previous time step as input. Then the hidden state is updated using the activation function.
Output layer: This layer produces the output or prediction for each time step.
This is the architecture of basic RNNs that have difficulties in learning long-range dependencies due to the vanishing gradient problem. To solve this problem, more advanced RNN architectures like LSTM, and GRU have been developed. You can learn more about Recurrent Neural Networks from here.
Generative Adversarial Network(GANs)
GANs are a special type of deep learning model that is designed for generating new, synthetic data samples which resemble the given training dataset. It has the ability to generate realistic, high-quality data samples in various domains such as Image, audio, text, and more.
This model consists of two neural networks, the Generator and the discriminator.
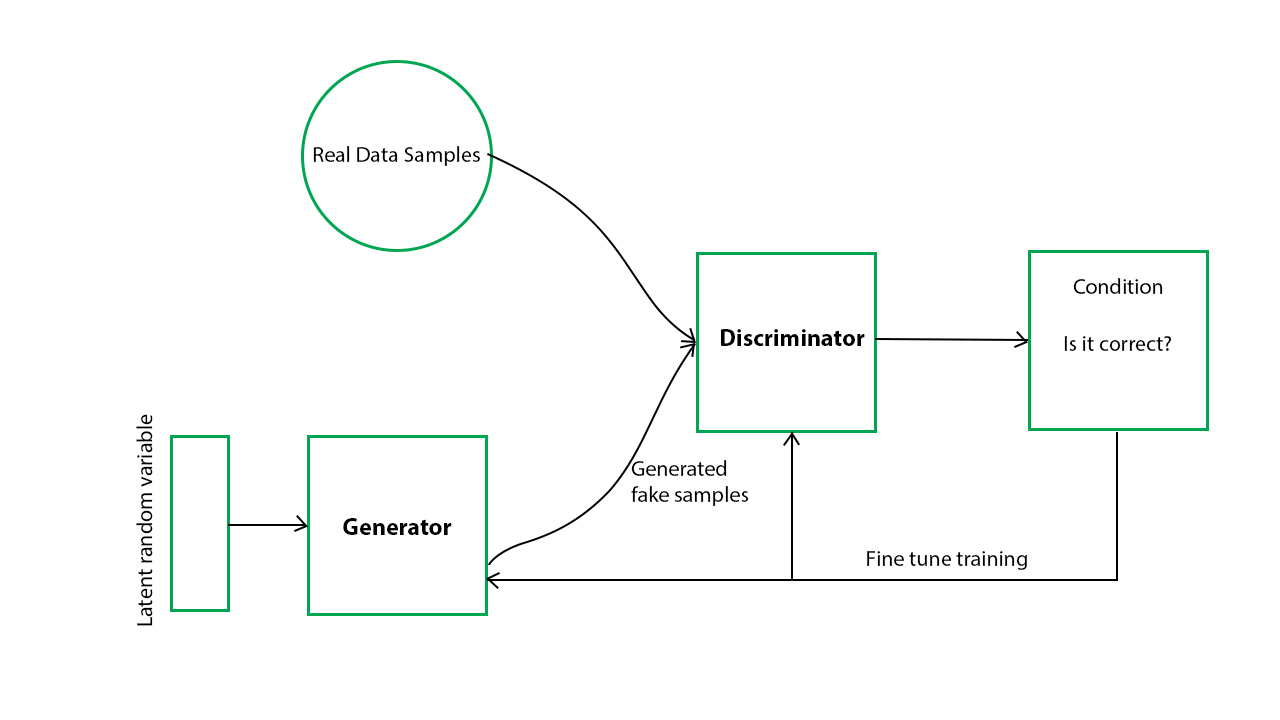
Generator: The generator network attempts to produce artificial data that resembles actual data from the training set using random noise as input. For instance, if the GAN is trained on cat photos, the generator will try to produce realistic-looking cat images.
Discriminator: This network functions as a binary classifier. It accepts created data from the generator and actual data from the training set as input. It aims to differentiate between authentic and false data. In essence, it learns to distinguish between images that came from the original dataset and those that were created by the generator.
These two networks compete with one another during the GAN training process. The generator aims to create sufficiently convincing data that the discriminator will mistakenly label it as real. The discriminator, on the other hand, aims to better discern between authentic and fraudulent data. The discriminator gets better at spotting fake data as training continues, while the generator produces more accurate data. This adversarial process pushes The GAN to produce increasingly realistic synthetic data.
The above architecture is the basic architecture of GANs. It has many variants, such as Conditional GANs, CycleGANs, Wasserstein GANs, Deep Convolutional GANs, and so on. Image synthesis, Data Augmentation, Style transfer, Image to Image Translation, Super Resolution, 3D object generation, Drug discovery, and anomaly detection are some applications of GANs. You can learn here
Deep Learning Applications
Deep learning has a wide range of applications in various domains such as image, text, audio, time series data, and so on because of its ability to learn complex patterns and representations from large amounts of data. Let’s gather some knowledge about some of the applications of deep learning.
Computer Vision
Deep learning enables significant advancements in Computer vision. Let’s go deep into Computer vision applications.
Image Classification: Based on the content of images classify the image name. Convolutional Neural Network(CNN) has achieved state-of-the-art in the image classification problem.
Object Detection: Identifying and locating objects in an image or video R-CNN, Yolo and Yolo variants, SSD, and other models are used in the Object detection model.
Image Segmentation: Divide an image into multiple segments or regions. U-net, Mask R-CNN, DeepLab, and other models are used in image segmentation tasks.
Image Generation: Generating new images that resemble the given dataset GANs and Autoencoder are used in this perspective.
These are many other applications that exist and the number of applications is increasing day by day.
Natural Language Processing
Deep learning plays a significant achievement in Natural Language Processing (NLP) tasks. Let's dive deep.
Sentiment Analysis: Determining the emotion expressed in a text. CNN, RNN, and Transformer models can be used in sentiment analysis.
Text Classification: Categorizing the text for the predefined topic of texts. Spam detection, News categorization, and document tagging are examples of text classification. CNN, RNN, and transformer models are generally used in text classification tasks.
Language Translation: Translate one language to another automatically. Sequence-to-sequence models with attention, transformer-based models like Bert, and GPT are generally used in this perspective.
There are many other applications in NLP such as Text Summarization, Named Entity Recognition, Question Answering, Chatbot & Conversational AI, Language Modeling, Speech to text & text to speech, and so on.
Other Applications
Speech Recognition: It is the process of identifying and responding to the sounds produced by the human. It is an essential component of many applications such as virtual assistance, transcription services, voice command systems, and so on. Deep Neural Networks, RNN, Connectionist Temporal classification (CTC), Attention Mechanisms, and Transformer Models are used in this perspective.
Recommender Systems: This technique is used to provide personalized suggestions or recommendations to users. This system can be used in many applications, such as e-commerce, online advertising, content platforms, social networks, and so on. Mainly, three types of recommendation systems are Collaborative filtering, Content-Based Filtering, and Hybrid Methods. Reinforcement Learning, Context-aware recommendations, and Graph neural networks can be used in this perspective.
Fraud Detection: It means identifying unusual, suspicious activities that are different from normal behavior such as credit card fraud, insurance fraud, cyber attacks, and so on. Autoencoders, Variational Autoencoders(VAEs), Deep Belief Networks, RNN, GNN, and ensemble models are used in this perspective.
Conclusion
Today we have learned the introduction, the basic components of deep learning, types of Neural Networks, Different models and applications, and so on. The research on deep learning is exponentially growing. The scalability, Versatility, and Adaptability enable new applications to become more strength day after day. In the future, The architecture is improving, creating Transfer learning models, Explainability & interpretability of models, working in data privacy & security, and so on. The applications of deep learning are increasing day by day. Hope you enjoy this article and feel interested in the deep learning field with our deep learning tutorials and courses.