- Getting Started with Generative Artificial Intelligence
- Mastering Image Generation Techniques with Generative Models
- Generating Art with Neural Style Transfer
- Exploring Deep Dream and Neural Style Transfer
- A Guide to 3D Object Generation with Generative Models
- Text Generation with Generative Models
- Language Generation Models for Prompt Generation
- Chatbots with Generative AI Models
- Music Generation with Generative Models
- A Beginner’s Guide to Generative Design
- Video Generation with Generative Models
- Anime Generation with Generative Models
- Generative Adversarial Networks (GANs)
- Generative modeling using Variational AutoEncoders
- Reinforcement Learning for Generation
- Interactive Generative Systems
- Fashion Generation with Generative Models
- Story Generation with Generative Models
- Character Generation with Generative AI
- Generative Modeling for Simulation
- Data Augmentation Techniques with Generative Models
- Future Directions in Generative AI
Mastering Image Generation Techniques with Generative Models | Generative AI

Introduction
Generative AI models, Using deep learning methods like GANs, Diffusion, and DALL-E to make realistic images from big datasets has changed the way images are made forever. These models are used in computer vision, graphics, art, and design to help improve data and make images. There are still ethics problems, such as data privacy and bias. Proper planning and performance are needed to lower the risks that could happen.
Importance of Image Generation
Generative models are crucial for creating images in various fields, promoting creative expression, enriching data for machine learning models, and improving performance and generalization skills. They are used in medical research, gaming, entertainment, and autonomous car training. Generative models also enhance the reliability and safety of autonomous cars by producing synthetic data. Overall, their use transforms industries by promoting technical innovation, encouraging creativity, and strengthening data-driven decision-making.
Some of the image generation models are:
- Diffusion Models
- DALL-E
- Generative Adversarial Models (GANs)
Let’s dive into these models :
Diffusion Models:
The Diffusion Model is a probabilistic-generative model that uses random noise vectors to create realistic images through learnable transformations and noise injections.
- We use Denoising Diffusion Probabilistic Models (DDPM) to inject noise and subsequently denoise.
The Workflow:
Adding a noise to the image is done by iterating the process of addition of noises :

X0 is the real image, XT is the fully noised image
The same process of iteration goes for denoising an image:

XT is the fully noised image, X0 is the noise removed image
Diffusion Model Use Cases :
The Diffusion Model is based on two cases.
- Unconditioned Generation &
- Conditioned Generation
Unconditioned Generation: Image generation without external input or data, such as Human Face Synthesis and super-resolution, is achieved using the model itself.
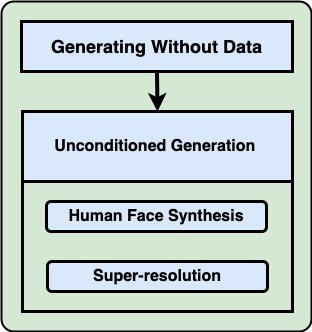
Unconditioned Image Generation
Conditioned Generation: The process involves the generation of an image using external input or data, such as text-to-image, image-painting, or text-guided image-to-image.
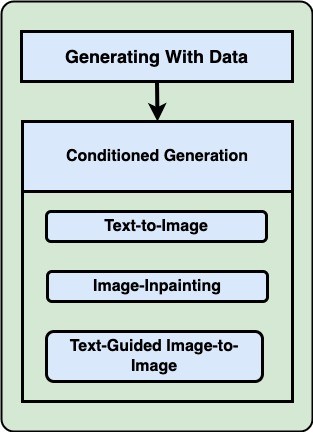
Implementation of Image Generation Using Diffusion
Let’s go through a simple code to understand things better:
Step 1:Installing Dependencies
This line installs the required Python packages using pip. The -q flag makes the installation process quiet, suppressing unnecessary output.
!pip install git+https://github.com/huggingface/diffusers transformers accelerate -qStep 2: Importing Libraries
These lines import necessary libraries for the code. StableDiffusionXLPipeline is imported from the diffusers package for using stable diffusion models. torch is imported for tensor computations.
import torch from diffusers import StableDiffusionXLPipeline
Step 3: Initializing Diffusion Model Pipeline
This line initializes a diffusion model pipeline using the StableDiffusionXLPipeline.from_pretrained()method. It loads a pre-trained model named "segmind/SSD-1B" and configures it to use 16-bit floating point precision (torch.float16) and safe tensors (use_safetensors=True) for efficient computation.
pipe = StableDiffusionXLPipeline.from_pretrained("segmind/SSD-1B", torch_dtype=torch.float16, use_safetensors=True, variant="fp16") pipe.to("cuda")
Step 4: Defining Prompts
These lines define the prompts for generating the image. prompt contains a positive prompt describing the desired content of the image, while neg_prompt contains a negative prompt describing undesirable qualities of the image.
#Moving Model to GPU pipe.to("cuda") # Your prompt here prompt = "An astronaut riding a green horse" # Negative prompt here neg_prompt = "ugly, blurry, poor quality"
Step 5:Generating Image
This line generates an image based on the provided prompts using the initialized diffusion model pipeline (pipe). It passes the positive prompt (prompt) and negative prompt (neg_prompt) to the model pipeline. The generated image is then stored in theimagevariable.
image = pipe(prompt=prompt, negative_prompt=neg_prompt).images[0] image
Generated Output Image:

DALL-E
OpenAI's DALL-E, DALL-E 2, and DALL-E 3 are text-to-image models that use deep learning to generate digital images from natural language descriptions. These models combine language and visual processing, enabling new possibilities in creative fields, communication, and education.
There are three ways to interact with photographs using the photographs API:
- producing original visuals in response to a written instruction (DALL·E 3 and DALL·E 2)
- Using a new text prompt (DALL·E 2 only), the model may be trained to replace specific portions of an existing picture to create altered versions of the images.
- Creating variants of an already-existing picture (DALL·E 2 only).
The Workflow:
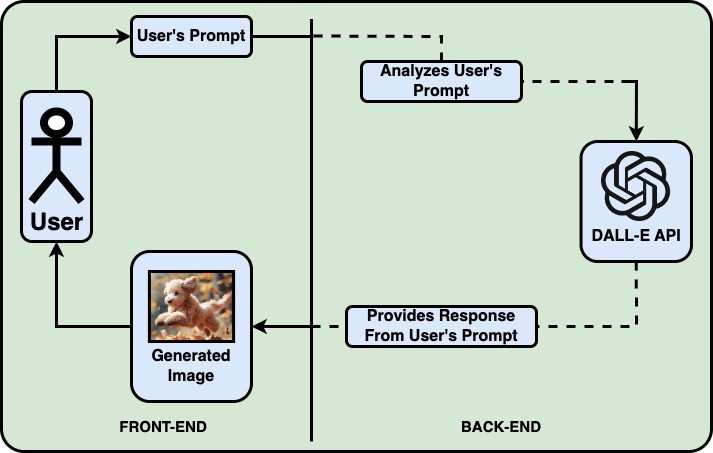
Simplified workflow of User's Interaction With the DALL-E API
Implementation of Image Generation Using DALL-E
This Python code utilizes the OpenAI API to generate images using the DALL-E model. Here's a summary of what each part of the code does:
- Imports necessary libraries: requests, json, and os.
- Retrieves the OpenAI API key from the environment variables.
- Defines the API endpoint for image generation (api_url) and sets headers including the API key.
- Constructs the data payload for the API request, specifying the DALL-E model to use, a prompt for generating the image (in this case, "An astronaut riding a horse"), number of images to generate (n), and desired size.
- Makes a POST request to the OpenAI API with the specified data.
- Checks if the request was successful (status code 200), and if so, prints the URL of the generated image(s).
- If the request fails, it prints out the error status code and the error response.
Let’s go through a simple code to understand things better:
The Code Implementation on Python File.
import requests import json import os # Replace with your OpenAI API key OPENAI_API_KEY = os.getenv('OPENAI_API_KEY') # Define the API endpoint and request payload api_url = 'https://api.openai.com/v1/images/generations' headers = { 'Content-Type': 'application/json', 'Authorization': f'Bearer {OPENAI_API_KEY}' } data = { "model": "dall-e-3", "prompt": "an astronaut riding a horse", "n": 1, "size": "1024x1024" } # Make the API request response = requests.post(api_url, headers=headers, data=json.dumps(data)) # Check if the request was successful if response.status_code == 200: result = response.json() print("Generated image URL:", result['data'][0]['url']) else: print("Error:", response.status_code, response.text) Generated Output Image:

The Generative Adversarial Models (GANs)
Generative Adversarial Networks(GANs), are based on the concept of forcing two Neural Networks into competition.
- One will generate images similar to the training data.
- The other person will identify which training images have been generated.
The Workflow:
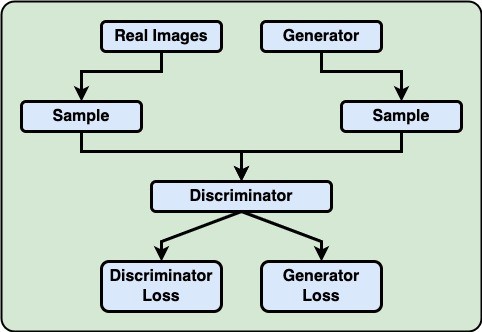
Generative Adversarial Models (GANs)
Here:
- The generated and Real images are classified using the discriminator.
- Data passed through when it is unable to distinguish between generated and Real data is known as the discriminator loss.
- The discriminator's ability to distinguish between generated and genuine data is known as the generative loss.
Implementation of Image Generation Using GANs
Implementation of Generative AI With GANs has already been done on our website. If you want to know the details and implement the coding click the link to know the details.
Conclusion
Generative AI techniques like GANs and diffusion models offer potential for innovation and machine learning in various industries, but ethical considerations necessitate responsible development and deployment for informed decision-making and risk mitigation.