- Getting Started with Generative Artificial Intelligence
- Mastering Image Generation Techniques with Generative Models
- Generating Art with Neural Style Transfer
- Exploring Deep Dream and Neural Style Transfer
- A Guide to 3D Object Generation with Generative Models
- Text Generation with Generative Models
- Language Generation Models for Prompt Generation
- Chatbots with Generative AI Models
- Music Generation with Generative Models
- A Beginner’s Guide to Generative Design
- Video Generation with Generative Models
- Anime Generation with Generative Models
- Generative Adversarial Networks (GANs)
- Generative modeling using Variational AutoEncoders
- Reinforcement Learning for Generation
- Interactive Generative Systems
- Fashion Generation with Generative Models
- Story Generation with Generative Models
- Character Generation with Generative AI
- Generative Modeling for Simulation
- Data Augmentation Techniques with Generative Models
- Future Directions in Generative AI
Generating Art with Neural Style Transfer | Generative AI

Introduction
Neural Style Transfer (NST) is a computer method for integrating stylistic features from two images to make new works of art. NST breaks down material and style into separate models using convolutional neural networks, which are based on how humans think. This new way of doing things can be used in graphic creation, augmented reality, and image editing. NST has interested artists, researchers, and scientists because it gives them ways to try new things and express themselves. This study goes into detail about the ideas, methods, and artistic options of NST and how it has changed digital art.
Importance of Generating Art with Neural Style Transfer
Neural Style Transfer (NST) is an innovative technique that lets artists combine different visual styles. This opens the door to an age of innovation and pushing the limits. It connects art and technology and shows how creativity and machine intelligence can work together to make something better. NST is useful for more than just art. It can also be used in graphic design, promotion, and content creation to make things and digital media look better. For example, it shows how artificial intelligence is changing over time and how human creativity and machine intelligence can work together.
The Generating Art with Neural Style Transfer are :
VQGAN & CLIP
Let's dive into these VQGAN & CLIP
The collaboration of VQGAN and CLIP represents a major AI breakthrough in image generation and interpretation. VQGAN generates images guided by CLIP's evaluation of text prompts. VQGAN's innovative two-stage structure, using a codebook for visual representation, and CLIP's learning of visual concepts through language supervision, showcase their combined generative and interpretive capabilities, advancing AI-driven image synthesis and comprehension.
VQGAN: The structure of VQGAN is split into two stages. First, a codebook creates an intermediate representation, which is then sent to a transformer. It's not like traditional pixel-by-pixel methods because it uses codewords from the learned codebook instead. This keeps reductions from happening and solves scaling problems in transformers. By using vector quantization, VQGAN creates a codebook of visually rich contexts, which makes the computation simpler. This is done by grouping vectors together and representing each group with its center using clustering algorithms. Basically, VQGAN makes it easier to make images quickly and better models of visual compositions.
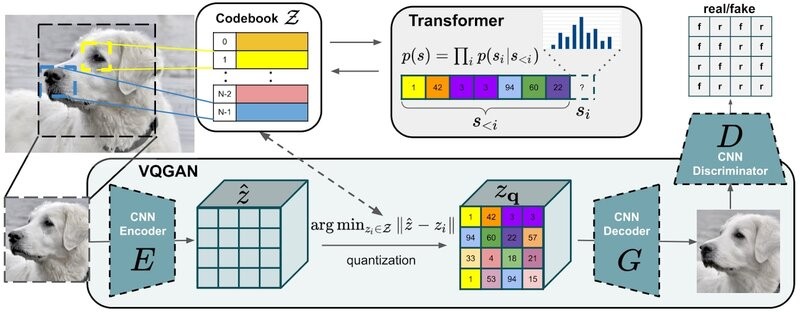
CLIP: CLIP is an AI model that select the best caption from a list for a given image. It learns general images with the help of natural language supervision. This lets it do great zero-shot work on an array of image classification tasks without directly optimizing for standards like CIFAR. This is done by making a simple pre-training task bigger and learning how to connect text and images.
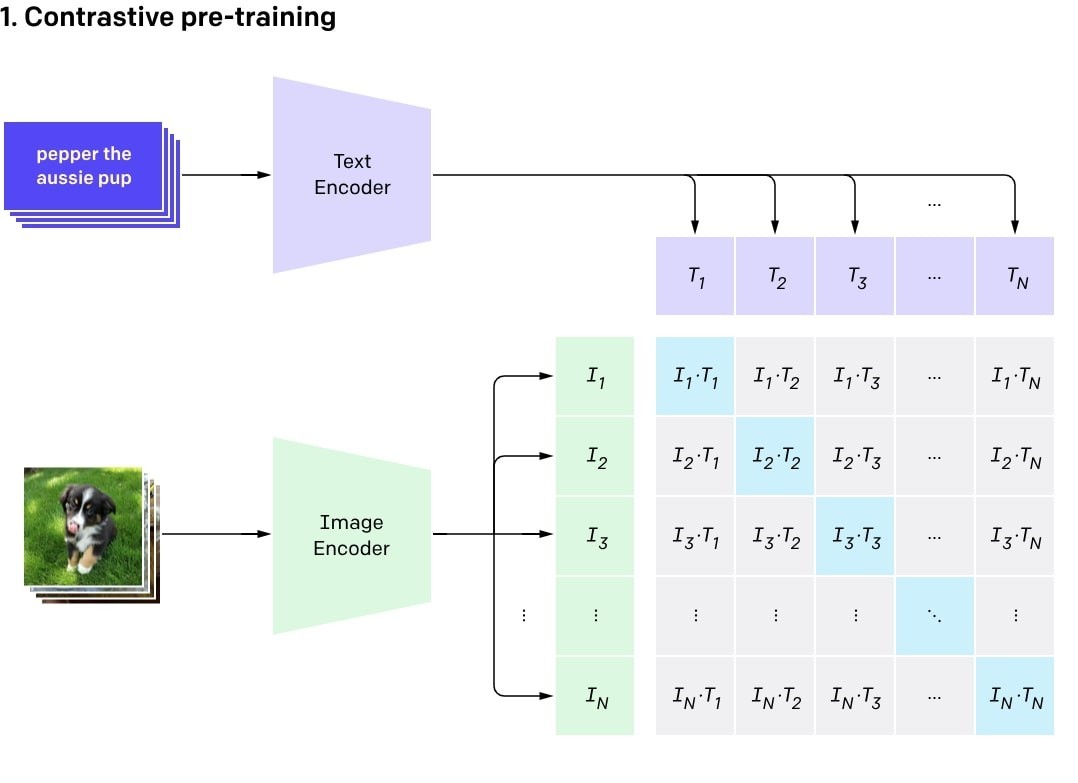
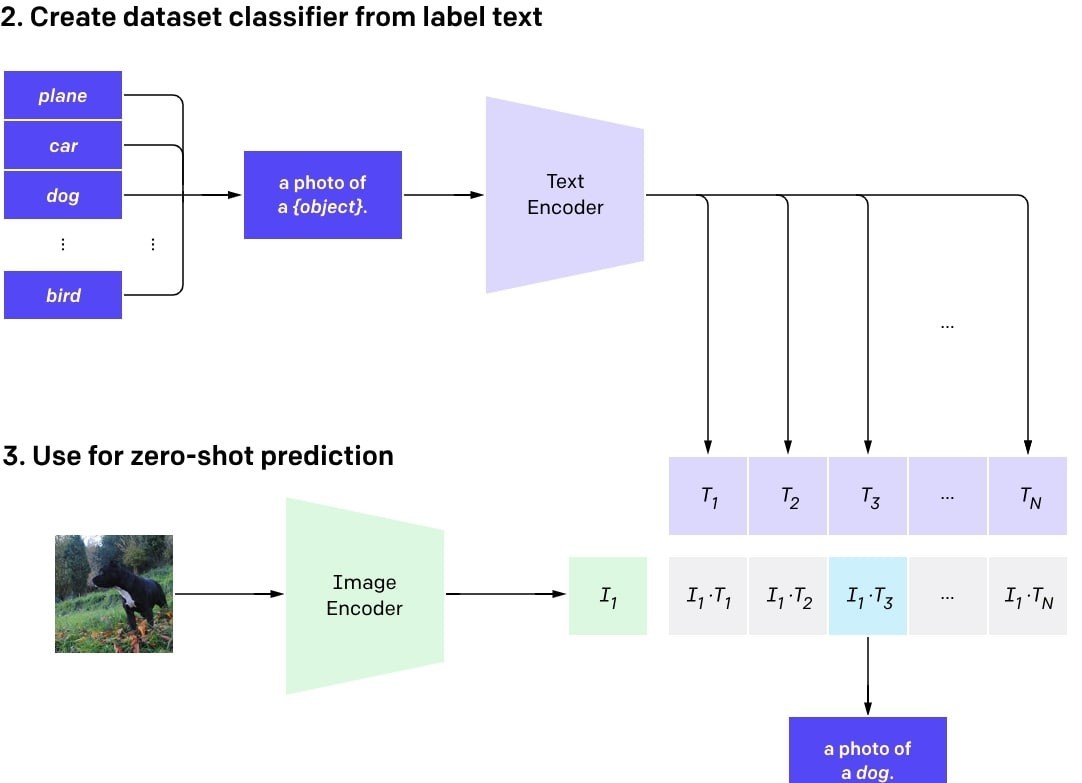
CLIP trains text and image encoders to learn feature representations. It computes scaled cosine similarity, minimizing diagonal values to align image features with text features.
How do VQGAN and CLIP work together?
CLIP guides VQGAN to generate images that closely match given text prompts. (CLIP is the perceptor, and VQGAN is the image generator.) VQGAN generates realistic images from noise vectors, while CLIP extracts image and text features and computes their similarity using cosine similarity. Utilizing CLIP's suggestions, VQGAN explores its hidden space to generate images that match the given text prompts well.
The Workflow:
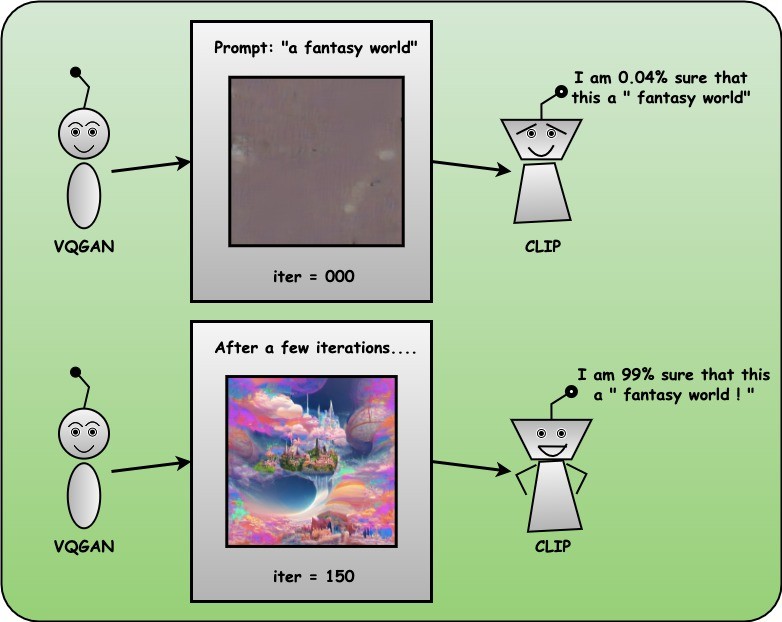
Implementation of Generating Art VQGAN and CLIP
Let's go through a simple code to understand things better:
Step 1: Efficient Installation Script for CLIP and Taming Transformers
!pip install --user torch==1.9.0 torchvision==0.10.0 torchaudio==0.9.0 torchtext==0.10.0!git clone https://github.com/openai/CLIP
# !pip install taming-transformers
!git clone https://github.com/CompVis/taming-transformers.git
!pip install ftfy regex tqdm omegaconf pytorch-lightning
!pip install kornia
!pip install imageio-ffmpeg
!pip install einops
!mkdir steps
!!pip install pynvml
Step 2: Import Libraries
import osimport torch
torch.hub.download_url_to_file('https://heibox.uni-heidelberg.de/d/a7530b09fed84f80a887/files/?p=%2Fconfigs%2Fmodel.yaml&dl=1',
'vqgan_imagenet_f16_16384.yaml')
torch.hub.download_url_to_file('https://heibox.uni-heidelberg.de/d/a7530b09fed84f80a887/files/?p=%2Fckpts%2Flast.ckpt&dl=1',
'vqgan_imagenet_f16_16384.ckpt')
import argparse
import math
from pathlib import Path
import sys
sys.path.insert(1, './taming-transformers')
# from IPython import display
from base64 import b64encode
from omegaconf import OmegaConf
from PIL import Image
import matplotlib.pyplot as plt
from taming.models import cond_transformer, vqgan
import taming.modules
from torch import nn, optim
from torch.nn import functional as F
from torchvision import transforms
from torchvision.transforms import functional as TF
from tqdm.notebook import tqdm
from CLIP import clip
import kornia.augmentation as K
import numpy as np
import imageio
from PIL import ImageFile, Image
from urllib.request import urlopen
ImageFile.LOAD_TRUNCATED_IMAGES = True
from pynvml.smi import nvmlInit, nvmlDeviceGetHandleByIndex,
nvmlDeviceGetUtilizationRates
nvmlInit()
handle = nvmlDeviceGetHandleByIndex(0)
import warnings
warnings.filterwarnings("ignore")
Step 3: Downloading Garden and Cabin Images with PyTorch Hub
torch.hub.download_url_to_file('https://images.pexels.com/photos/158028/bellingrath-gardens-alabama-landscape-scenic-158028.jpeg',
'garden.jpeg')
torch.hub.download_url_to_file('https://images.pexels.com/photos/803975/pexels-photo-803975.jpeg',
'cabin.jpeg')
Step 4: Helper functions
The provided code implements image resampling functions in PyTorch. It includes functions for computing the sinc function, applying the Lanczos kernel, generating a ramp signal, and resampling an input image tensor using Lanczos resampling followed by bicubic interpolation.
defsinc(x):return torch.where(x != 0, torch.sin(math.pi * x) / (math.pi * x), x.new_ones([]))
deflanczos(x, a):
cond = torch.logical_and(-a < x, x < a)
out = torch.where(cond, sinc(x) * sinc(x/a), x.new_zeros([]))
return out / out.sum()
deframp(ratio, width):
n = math.ceil(width / ratio + 1)
out = torch.empty([n])
cur = 0
for i in range(out.shape[0]):
out[i] = cur
cur += ratio
return torch.cat([-out[1:].flip([0]), out])[1:-1]
defresample(input, size, align_corners=True):
n, c, h, w = input.shape
dh, dw = size
input = input.view([n * c, 1, h, w])
if dh < h:
kernel_h = lanczos(ramp(dh / h, 2), 2).to(input.device, input.dtype)
pad_h = (kernel_h.shape[0] - 1) // 2
input = F.pad(input, (0, 0, pad_h, pad_h), 'reflect')
input = F.conv2d(input, kernel_h[None, None, :, None])
if dw < w:
kernel_w = lanczos(ramp(dw / w, 2), 2).to(input.device, input.dtype)
pad_w = (kernel_w.shape[0] - 1) // 2
input = F.pad(input, (pad_w, pad_w, 0, 0), 'reflect')
input = F.conv2d(input, kernel_w[None, None, None, :])
input = input.view([n, c, h, w])
return F.interpolate(input, size, mode='bicubic', align_corners=align_corners)
The code defines two custom autograd functions in PyTorch. (ReplaceGrad) swaps gradients during backpropagation, while (ClampWithGrad) clamps input tensors while maintaining gradient flow. These functions enable nuanced gradient manipulation, enhancing PyTorch's flexibility.
classReplaceGrad(torch.autograd.Function):@staticmethod
defforward(ctx, x_forward, x_backward):
ctx.shape = x_backward.shape
return x_forward
@staticmethod
defbackward(ctx, grad_in):
returnNone, grad_in.sum_to_size(ctx.shape)
replace_grad = ReplaceGrad.apply
classClampWithGrad(torch.autograd.Function):
@staticmethod
defforward(ctx, input, min, max):
ctx.min = min
ctx.max = max
ctx.save_for_backward(input)
return input.clamp(min, max)
@staticmethod
defbackward(ctx, grad_in):
input, = ctx.saved_tensors
return grad_in * (grad_in * (input - input.clamp(ctx.min, ctx.max)) >= 0), None, None
clamp_with_grad = ClampWithGrad.apply
The code facilitates text generation tasks with prompt embeddings (Prompt) and vector quantization (vector_quantize). It includes a function for parsing prompt strings (parse_prompt). These tools streamline text manipulation within neural network models.
defvector_quantize(x, codebook):d = x.pow(2).sum(dim=-1, keepdim=True) + codebook.pow(2).sum(dim=1) - 2 * x @ codebook.T
indices = d.argmin(-1)
x_q = F.one_hot(indices, codebook.shape[0]).to(d.dtype) @ codebook
return replace_grad(x_q, x)
classPrompt(nn.Module):
def__init__(self, embed, weight=1., stop=float('-inf')):
super().__init__()
self.register_buffer('embed', embed)
self.register_buffer('weight', torch.as_tensor(weight))
self.register_buffer('stop', torch.as_tensor(stop))
defforward(self, input):
input_normed = F.normalize(input.unsqueeze(1), dim=2)
embed_normed = F.normalize(self.embed.unsqueeze(0), dim=2)
dists = input_normed.sub(embed_normed).norm(dim=2).div(2).arcsin().pow(2).mul(2)
dists = dists * self.weight.sign()
return self.weight.abs() * replace_grad(dists, torch.maximum(dists, self.stop)).mean()
defparse_prompt(prompt):
vals = prompt.rsplit(':', 2)
vals = vals + ['', '1', '-inf'][len(vals):]
return vals[0], float(vals[1]), float(vals[2])
The (MakeCutouts) module generates cutout images by applying various augmentation techniques and averaging pooled versions of the input. It then adds optional noise before returning the cutouts, aiding in robustness for image tasks.
classMakeCutouts(nn.Module):def__init__(self, cut_size, cutn, cut_pow=1):
super().__init__()
self.cut_size = cut_size
self.cutn = cutn
self.cut_pow = cut_pow
self.augs = nn.Sequential(
K.RandomAffine(degrees=15, translate=0.1, p=0.7, padding_mode='border'),
K.RandomPerspective(0.7,p=0.7),
K.ColorJitter(hue=0.1, saturation=0.1, p=0.7),
K.RandomErasing((.1, .4), (.3, 1/.3), same_on_batch=True, p=0.7),
)
self.noise_fac = 0.1
self.av_pool = nn.AdaptiveAvgPool2d((self.cut_size, self.cut_size))
self.max_pool = nn.AdaptiveMaxPool2d((self.cut_size, self.cut_size))
defforward(self, input):
slideY, slideX = input.shape[2:4]
max_size = min(slideX, slideY)
min_size = min(slideX, slideY, self.cut_size)
cutouts = []
for _ in range(self.cutn):
cutout = (self.av_pool(input) + self.max_pool(input))/2
cutouts.append(cutout)
batch = self.augs(torch.cat(cutouts, dim=0))
if self.noise_fac:
facs = batch.new_empty([self.cutn, 1, 1, 1]).uniform_(0, self.noise_fac)
batch = batch + facs * torch.randn_like(batch)
return batch
The (load_vqgan_model) function initializes and loads a VQGAN-based model from given configuration and checkpoint paths. It supports various model types, removes the loss function, and returns the initialized model instance. This function simplifies loading and configuring VQGAN models for image generation.
defload_vqgan_model(config_path, checkpoint_path):config = OmegaConf.load(config_path)
if config.model.target == 'taming.models.vqgan.VQModel':
model = vqgan.VQModel(**config.model.params)
model.eval().requires_grad_(False)
model.init_from_ckpt(checkpoint_path)
elif config.model.target == 'taming.models.vqgan.GumbelVQ':
model = vqgan.GumbelVQ(**config.model.params)
model.eval().requires_grad_(False)
model.init_from_ckpt(checkpoint_path)
elif config.model.target == 'taming.models.cond_transformer.Net2NetTransformer':
parent_model = cond_transformer.Net2NetTransformer(**config.model.params)
parent_model.eval().requires_grad_(False)
parent_model.init_from_ckpt(checkpoint_path)
model = parent_model.first_stage_model
else:
raise ValueError(f'unknown model type: {config.model.target}')
del model.loss
return model
The (resize_image) function resizes an input image while preserving its aspect ratio and quality using Lanczos interpolation.
defresize_image(image, out_size):ratio = image.size[0] / image.size[1]
area = min(image.size[0] * image.size[1], out_size[0] * out_size[1])
size = round((area * ratio)**0.5), round((area / ratio)**0.5)
return image.resize(size, Image.LANCZOS)
Step 5: Download models
model_name = "vqgan_imagenet_f16_16384"
images_interval = 50
width = 512
height = 512
init_image = ""
seed = 42
BASE_PATH = '../input/flickr-image-dataset/flickr30k_images/flickr30k_images/'
args = argparse.Namespace(
noise_prompt_seeds=[],
noise_prompt_weights=[],
size=[width, height],
init_image=init_image,
init_weight=0.,
clip_model='ViT-B/32',
vqgan_config=f'{model_name}.yaml',
vqgan_checkpoint=f'{model_name}.ckpt',
step_size=0.13,
cutn=32,
cut_pow=1.,
display_freq=images_interval,
seed=seed,
)
device = torch.device('cuda:0'if torch.cuda.is_available() else'cpu')
print('Using device:', device)
model = load_vqgan_model(args.vqgan_config, args.vqgan_checkpoint).to(device)
perceptor = clip.load(args.clip_model, jit=False)[0].eval().requires_grad_(False).to(device)
Step 6: Interence
The (inference) function generates images from text prompts using VQGAN and CLIP models. It optimizes the generated image iteratively and saves the frames as a video file.
definference(text,seed,
step_size,
max_iterations,
width,
height,
init_image,
init_weight,
target_images,
cutn,
cut_pow,
video_file
):
all_frames = []
size=[width, height]
texts = text
init_weight=init_weight
if init_image:
init_image = init_image
else:
init_image = ""
if target_images:
target_images = target_images
else:
target_images = ""
max_iterations = max_iterations
model_names={"vqgan_imagenet_f16_16384": 'ImageNet 16384',
"vqgan_imagenet_f16_1024":"ImageNet 1024",
'vqgan_openimages_f16_8192':'OpenImages 8912',
"wikiart_1024":"WikiArt 1024",
"wikiart_16384":"WikiArt 16384",
"coco":"COCO-Stuff",
"faceshq":"FacesHQ",
"sflckr":"S-FLCKR"}
name_model = model_names[model_name]
if target_images == "None"ornot target_images:
target_images = []
else:
target_images = target_images.split("|")
target_images = [image.strip() for image in target_images]
texts = [phrase.strip() for phrase in texts.split("|")]
if texts == ['']:
texts = []
if texts:
print('Using texts:', texts)
if target_images:
print('Using image prompts:', target_images)
if seed isNoneor seed == -1:
seed = torch.seed()
else:
seed = seed
torch.manual_seed(seed)
print('Using seed:', seed)
cut_size = perceptor.visual.input_resolution
f = 2**(model.decoder.num_resolutions - 1)
make_cutouts = MakeCutouts(cut_size, cutn, cut_pow=cut_pow)
toksX, toksY = size[0] // f, size[1] // f
sideX, sideY = toksX * f, toksY * f
if args.vqgan_checkpoint == 'vqgan_openimages_f16_8192.ckpt':
e_dim = 256
n_toks = model.quantize.n_embed
z_min = model.quantize.embed.weight.min(dim=0).values[None, :, None, None]
z_max = model.quantize.embed.weight.max(dim=0).values[None, :, None, None]
else:
e_dim = model.quantize.e_dim
n_toks = model.quantize.n_e
z_min = model.quantize.embedding.weight.min(dim=0).values[None, :, None, None]
z_max = model.quantize.embedding.weight.max(dim=0).values[None, :, None, None]
if init_image:
if'http'in init_image:
img = Image.open(urlopen(init_image))
else:
img = Image.open(init_image)
pil_image = img.convert('RGB')
pil_image = pil_image.resize((sideX, sideY), Image.LANCZOS)
pil_tensor = TF.to_tensor(pil_image)
z, *_ = model.encode(pil_tensor.to(device).unsqueeze(0) * 2 - 1)
else:
one_hot = F.one_hot(torch.randint(n_toks, [toksY * toksX], device=device), n_toks).float()
# z = one_hot @ model.quantize.embedding.weight
if args.vqgan_checkpoint == 'vqgan_openimages_f16_8192.ckpt':
z = one_hot @ model.quantize.embed.weight
else:
z = one_hot @ model.quantize.embedding.weight
z = z.view([-1, toksY, toksX, e_dim]).permute(0, 3, 1, 2)
z = torch.rand_like(z)*2
z_orig = z.clone()
z.requires_grad_(True)
opt = optim.Adam([z], lr=step_size)
normalize = transforms.Normalize(mean=[0.48145466, 0.4578275, 0.40821073],
std=[0.26862954, 0.26130258, 0.27577711])
pMs = []
for prompt in texts:
txt, weight, stop = parse_prompt(prompt)
embed = perceptor.encode_text(clip.tokenize(txt).to(device)).float()
pMs.append(Prompt(embed, weight, stop).to(device))
for prompt in target_images:
path, weight, stop = parse_prompt(prompt)
img = Image.open(path)
pil_image = img.convert('RGB')
img = resize_image(pil_image, (sideX, sideY))
batch = make_cutouts(TF.to_tensor(img).unsqueeze(0).to(device))
embed = perceptor.encode_image(normalize(batch)).float()
pMs.append(Prompt(embed, weight, stop).to(device))
for seed, weight in zip(args.noise_prompt_seeds, args.noise_prompt_weights):
gen = torch.Generator().manual_seed(seed)
embed = torch.empty([1, perceptor.visual.output_dim]).normal_(generator=gen)
pMs.append(Prompt(embed, weight).to(device))
defsynth(z):
if args.vqgan_checkpoint == 'vqgan_openimages_f16_8192.ckpt':
z_q = vector_quantize(z.movedim(1, 3), model.quantize.embed.weight).movedim(3, 1)
else:
z_q = vector_quantize(z.movedim(1, 3), model.quantize.embedding.weight).movedim(3, 1)
return clamp_with_grad(model.decode(z_q).add(1).div(2), 0, 1)
@torch.no_grad()
defcheckin(i, losses):
losses_str = ', '.join(f'{loss.item():g}'for loss in losses)
tqdm.write(f'i: {i}, loss: {sum(losses).item():g}, losses: {losses_str}')
out = synth(z)
# TF.to_pil_image(out[0].cpu()).save('progress.png')
# display.display(display.Image('progress.png'))
res = nvmlDeviceGetUtilizationRates(handle)
print(f'gpu: {res.gpu}%, gpu-mem: {res.memory}%')
defascend_txt():
# global i
out = synth(z)
iii = perceptor.encode_image(normalize(make_cutouts(out))).float()
result = []
if init_weight:
result.append(F.mse_loss(z, z_orig) * init_weight / 2)
#result.append(F.mse_loss(z, torch.zeros_like(z_orig)) * ((1/torch.tensor(i*2 + 1))*init_weight) / 2)
for prompt in pMs:
result.append(prompt(iii))
img = np.array(out.mul(255).clamp(0, 255)[0].cpu().detach().numpy().astype(np.uint8))[:,:,:]
img = np.transpose(img, (1, 2, 0))
# imageio.imwrite('./steps/' + str(i) + '.png', np.array(img))
img = Image.fromarray(img).convert('RGB')
all_frames.append(img)
return result, np.array(img)
deftrain(i):
opt.zero_grad()
lossAll, image = ascend_txt()
if i % args.display_freq == 0:
checkin(i, lossAll)
loss = sum(lossAll)
loss.backward()
opt.step()
with torch.no_grad():
z.copy_(z.maximum(z_min).minimum(z_max))
return image
i = 0
try:
with tqdm() as pbar:
whileTrue:
image = train(i)
if i == max_iterations:
break
i += 1
pbar.update()
except KeyboardInterrupt:
pass
writer = imageio.get_writer(video_file + '.mp4', fps=20)
for im in all_frames:
writer.append_data(np.array(im))
writer.close()
# all_frames[0].save('out.gif',
# save_all=True, append_images=all_frames[1:], optimize=False, duration=80, loop=0)
return image
The (load_image) function loads an image file and returns its data as a NumPy array of integers.
defload_image( infilename ) :img = Image.open( infilename )
img.load()
data = np.asarray( img, dtype="int32" )
return data
The (display_result) function visualizes the provided image using Matplotlib, omitting axis labels.
defdisplay_result(img) :plt.figure(figsize=(9,9))
plt.imshow(img)
plt.axis('off')
Example:
The code generates an image of "skulls with glowing eyes" using the (inference) function and displays the result.
img = inference(text = 'A city during a rainy night',
seed = 2,
step_size = 0.12,
max_iterations = 700,
width = 512,
height = 512,
init_image = '',
init_weight = 0.004,
target_images = '',
cutn = 64,
cut_pow = 0.3,
video_file = "test1"
)
display_result(img)
Generated Output Image:

The code snippet creates an HTML video player to display the generated video file (test1.mp4). It encodes the video file into base64 format and embeds it into the HTML video tag to allow playback directly within the Jupyter Notebook environment.
from IPython.display import HTMLfrom base64 import b64encodemp4 = open('test1.mp4','rb').read()
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
HTML("""
<video width=500 loop="true" autoplay="autoplay" controls muted>
<source src="%s" type="video/mp4">
</video>
""" % data_url)
Conclusion
The fusion of VQGAN and CLIP in Neural Style Transfer represents a significant advancement in AI-driven art generation. This collaboration offers artists unprecedented flexibility to merge diverse visual styles seamlessly, ushering in a new era of creative exploration. The provided code streamlines the implementation process, empowering artists and technologists to harness the power of AI for innovative artistic expression. By bridging the gap between human creativity and machine intelligence, Generating Art with Neural Style Transfer paves the way for transformative possibilities in digital artistry and beyond, underscoring the profound impact of AI on shaping the future of creative endeavors.