- Medical Image Segmentation With UNET
- Real-Time License Plate Detection Using YOLOv8 and OCR Model
- Real-Time Human Pose Detection With YOLOv8 Models
- Customer Service Chatbot Using LLMs
- Document Summarization Using Sentencepiece Transformers
- Semantic Search Using Msmarco Distilbert Base & Faiss Vector Database
- Question Answer System Training With Distilbert Base Uncased
- Image Generation Model Fine Tuning With Diffusers Models
- Predictive Analytics on Business License Data Using Deep Learning
- Complete CNN Image Classification Models for Real Time Prediction
- Linear Regression Modeling for Soccer Player Performance Prediction in the EPL
- Insurance Pricing Forecast Using XGBoost Regressor
- Chatbots with Generative AI Models
- Nutritionist Generative AI Doctor using Gemini
- Cervical Cancer Detection Using Deep Learning
- Skin Cancer Detection Using Deep Learning
- Blood Cell Classification Using Deep Learning
- Glaucoma Detection Using Deep Learning
- Leaf Disease Detection Using Deep Learning
- Banana Leaf Disease Detection using Vision Transformer model
- Vegetable classification with Parallel CNN model
- Crop Disease Detection Using YOLOv8
- Automatic Eye Cataract Detection Using YOLOv8
- Voice Cloning Application Using RVC
- Learn to Build a Polynomial Regression Model from Scratch
- Loan Eligibility Prediction using Gradient Boosting Classifier
- BigMart Sales Prediction ML Project in Python
- Word2Vec and FastText Word Embedding with Gensim in Python
- Build Regression (Linear, Ridge, Lasso) Models in NumPy Python
- Build a Customer Churn Prediction Model using Decision Trees
- Build Regression Models in Python for House Price Prediction
- Credit Card Default Prediction Using Machine Learning Techniques
- Topic modeling using K-means clustering to group customer reviews
- NLP Project for Beginners on Text Processing and Classification
- Skip Gram Model Python Implementation for Word Embeddings
- Sentiment Analysis for Mental Health Using NLP & ML
- Time Series Analysis and Prediction of Healthcare Trends Using Gaussian Process Regression
- Build a Hybrid Recommender System in Python using LightFM
- Time Series Forecasting Using Multiple Linear Regression Model
- Build an Autoregressive and Moving Average Time Series Model
- Time Series Forecasting with ARIMA and SARIMAX Models in Python
- Build Multi-Class Text Classification Models with RNN and LSTM
- Build A Book Recommender System With TF-IDF And Clustering(Python)
- Multi-Modal Retrieval-Augmented Generation (RAG) with Text and Image Processing
- PyTorch Project to Build a GAN Model on MNIST Dataset
- Build ARCH and GARCH Models in Time Series using Python
- Human Action Recognition Using Image Preprocessing
- Time Series Analysis with Facebook Prophet Python and Cesium
- Build a Face Recognition System Using FaceNet in Python
- Build a Collaborative Filtering Recommender System in Python
- guest-post-30
- Image Segmentation using Mask R CNN with PyTorch
- Fusion Retrieval: Combining Vector Search and BM25 for Enhanced Document Retrieval
- HyDE-Powered Document Retrieval Using DeepSeek
- Graph-Enhanced Retrieval-Augmented Generation (GRAPH-RAG)
- Context Enrichment Window Around Chunks Using LlamaIndex
- Document Augmentation through Question Generation for Enhanced Retrieval
- Enhancing Document Retrieval with Contextual Overlapping Windows
- Corrective Retrieval-Augmented Generation (RAG) with Dynamic Adjustments
- Optimizing Chunk Sizes for Efficient and Accurate Document Retrieval Using HyDE Evaluation
- Sign language recognition

Linear Regression Modeling for Soccer Player Performance Prediction in the EPL
Linear regression is commonly used in machine learning to solve prediction problems. The aim of this project is to predict EPL football player scores based on various factors. Furthermore, this method helps us understand how to model soccer player performance based on different factors. We use Python to build the model, making it easy for beginners to learn about linear regression. In addition, this project uses real-world data to improve learning and practice regression analysis.
Project Overview
This project focuses on building a multiple linear regression model to predict EPL soccer player scores. We use a dataset that includes attributes like player costs, goals, and shots per game. Moreover, the goal is to establish meaningful relationships between these factors and a player's score. This analysis helps team managers and scouts make better recruitment decisions.
This project covers key machine-learning ideas. It teaches data cleaning and regression analysis. You also learn how to check if a model works well. Beginners get hands-on practice with linear regression. They also understand how to measure a model's performance.
Prerequisites
We suggest having a basic understanding of Python, statistics, and machine learning before starting this project. It's helpful to know about model evaluation, visualization, and data preparation methods. You will need libraries like Matplotlib, NumPy, Pandas, and Scikit-learn for this project. Understanding ordinary least squares (OLS) regression and regression analysis is also helpful.
You can easily write and execute Python code by using Google Colab or Jupyter Notebook to run the code. You also learn important statistics like R-squared, modified R-squared, and p-values. These help you better understand the model's results.
Approach
In this project, we use multiple linear regression to predict EPL football player scores. We chose this method because it is simple to use. It shows how factors like player costs, shots per game, and goals impact the player's score.
You can also use other methods to predict player performance. These methods include decision trees, random forests, or neural networks. However, linear regression provides a simple and clear model. It helps you easily understand the connections between features and results. This makes it an excellent choice for beginners.
Workflow and Methodology
The overall workflow of this project includes:
- Problem definition: Predicting EPL soccer player scores.
- Data collection and preprocessing: First, we collect and preprocess the data, ensuring it is clean and ready for modeling.
- Data splitting: Next, we split the dataset into training and testing sets.
- Model building: We build a multiple linear regression model using ordinary least squares (OLS) regression
- Model evaluation: Next, we check how the model performs using R-squared and mean-squared error (MSE).
The methodology involves:
- Data handling: Cleaning, transforming, and splitting the data.
- Model selection: Choosing the linear regression model due to its interpretability.
- Training and evaluation: Training the model and validating its performance on the test set.
Additionally, other methods, such as random forest regression or neural networks, could be used to solve the problem. However, we chose this algorithm because it is simple and explains how different features relate to the target variable.
Data Collection
Data Preparation
First, we analyzed some players from EPL teams to create a dataset. After completing the analysis, we created a dataset with specific features. Moreover, the features we included in our dataset are:
- Player's Name
- Club
- Distance Covered (in Kms)
- Goals per Minute Ratio
- Shots per Game
- Agent Fee
- BMI
- Cost
- Previous Club Cost
- Height (Squared)
We analyzed these features and added the values of all players' characteristics to the dataset. The final dataset is now ready for use in the model.
Data Preparation Workflow
The data preparation workflow involves several steps to ensure the dataset is properly structured for the model:
Code Explanation
Mounting Google Drive
You can mount your Google Drive in a Google Colab notebook with this block of code. This lets users easily view files saved in Google Drive within Colab. They can modify and analyze the data. Users can also train models using the files.
from google.colab import drive
drive.mount('/content/drive')
import warnings
warnings.filterwarnings('ignore')Install required packages
These commands install the necessary Python libraries. They include numpy, seaborn, matplotlib, statsmodels, pandas, scipy, and scikit-learn. We use 'pip' to install them. This sets up the environment for data analysis, modeling, and visualization.
!pip install numpy !pip install seaborn !pip install matplotlib !pip install statsmodels !pip install pandas !pip install scipy !pip install scikit_learn
Import required packages
This code imports libraries for handling data, modeling, and creating visuals. It prepares the environment for data analysis and plotting tasks.
import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split import statsmodels.api as sm import seaborn as sns from scipy import stats import scipy from matplotlib.pyplot import figure
Data Reading from Different Sources
- Files: In many cases, the data is stored in the local system. To read the data from the local system, specify the correct path and filename.
CSV format
- Comma-separated values, also known as CSV, are a specific way to store data in a table structure format. We use CSV Formated data in this project.
- Use the following code to read data from CSV file using pandas.
- With appropriate data, pd.read_csv() function will read the data and store it in df variable.
- If you get FileNotFoundError or No such file or directory, try checking the path provided in the function. Moreover, it's possible that Python is not able to find the file or directory at a given location.
Load the data
data = pd.read_csv('/content/drive/MyDrive/Aionlinecourse/EPL_Soccer_Dataset.csv')
data.head(10)Data for columns
data.columns
Data analysis and visualization
Data Dictionary
- PlayerName: Player Name
- Club: Club of the player
- DistanceCovered(InKms): Average Kms distance covered by the player in each game
- Goals: Average Goals per match
- MinutestoGoalRatio: Minutes
- ShotsPerGame: Average shots taken per game
- AgentCharges: Agent Fees in h
- BMI: Body-Mass index
- Cost: Cost of each player in hundred thousand dollars
- PreviousClubCost: Previous club cost in hundred thousand dollars
- Height: Height of player in cm
- Weight: Weight of player in kg
- Score: Average score per match
Exploratory Data Analysis
Exploratory Data Analysis, commonly known as EDA, is a technique to analyze the data with visuals. Additionally, it involves using statistics and visual techniques to identify particular trends in data.
EDA helps understand data patterns and find odd values. It also checks assumptions. The main goal is to analyze the data before making any decision about it.
Dataframe Information
The dataframe.info() method shows details about the DataFrame. This includes index type, columns, non-null values, and memory usage.
It can be used to get basic info, look for missing values, and get a sense of each variable's format.
data.info()
There are a total of 254 rows and 13 columns in the EPL Soccer Dataset. Interestingly, there are no null values in the dataset. Out of 13 columns, 10 are float type, and 1 is integer type. The remaining 2 have object types.
Dataframe Description
- To generate descriptive statistics pandas.dataframe.describe() function is used.
- Descriptive statistics summarize the central point, spread, and shape of a dataset. They ignore any NaN values.
- It is used to get a simple overview of the data. This includes checking how different variables spread out. It also looks at sudden changes between the minimum, 25th, 50th, 75th, and maximum values for each variable.
- The quartiles provide an excellent insight into the range of a set of data. You can easily see where your data fits in the range. By knowing the 25th, 50th, and 75th percentiles, you can find out which quartile your data falls into
- The 25th percentile is also referred to as the first, or lower, quartile. The 25th percentile is the figure at which 25% of the data falls below it and 75% of the answers fall above it.
- The Median is also known as the 50th percentile. The median divides the set of data in half. Half of the data points are below the median, while the other half are above it.
- The 75th percentile is often referred to as the third, or upper, quartile. In other words, the 75th percentile is the value at which 25% of the responses are higher and 75% of the answers are lower.
Descriptive statistics for quantitative variables
- DataFrame.count: Count the number of non-NA/null observations
- DataFrame.max: Maximum of the values in the object
- DataFrame.min: Minimum of the values in the object
- DataFrame.mean: Mean of the values
- DataFrame.std: Standard deviation of the observations
- DataFrame.select_dtypes: Subset of a DataFrame including/excluding columns based on their type
data.describe()
Relationship between Cost and Score
Score and Cost have a 96% correlation, making it a significant variable. Cost can be used as the predictor for simple linear regression. The scatter plot shows a clear linear relationship between them.
To see this relationship visually, let's plot the scatter plot for Cost and Score.
figure(figsize=(8, 6), dpi=80)
plt.scatter(data['Cost'], data['Score'])
# define the label
plt.xlabel("Cost")
plt.ylabel("Score")
plt.title("Scatter plot: Cost vs. Score")Splitting the dataset into training data and test data
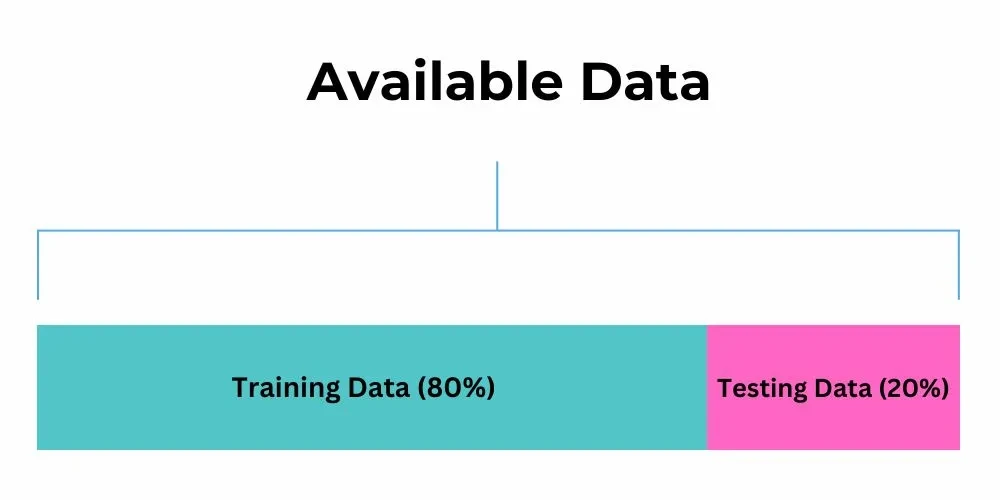
After the data points are collected, they are split into two sets, called train and test. The model is trained on the training data. It is then tested on new data to see how well it performs and check if it fits too well or poorly.
Underfitting and Overfitting
Underfitting: Underfitting happens when a model is too simple to learn the data's patterns. This leads to poor results on both training and testing data. It often happens when the model is too basic for complex data or lacks sufficient features. To fix underfitting, you can make the model more complex or add relevant features.
Overfitting: Overfitting happens when a model is too complex, learning from noise and errors in the training data. This causes it to perform well on training data but poorly on testing data, as it fails to generalize. To fix overfitting, try reducing the model's complexity. You can also use techniques like regularization or more training data.
x=data['Cost'] y=data['Score'] #The dataset is split into 80% training data and 20% testing data x_train, x_test, y_train, y_test = train_test_split(x, y, train_size = 0.80, test_size = 0.20, random_state = 100)
Choose an AI Model
For this project, we chose multiple linear regression as the AI model. We chose this model because it's simple and easy to understand. It helps explain the relationship between features and the target. It shows how factors like player cost, goals, and distance affect the player's score. This makes it an ideal choice for beginners in machine learning.
Stats models approach to regression
Let's get to our case. We will use Ordinary Least Squares from the statsmodels library to model the link between Cost and Scores.