- Introduction to Computer Vision
- Image Preprocessing for Computer Vision
- Mathematical Analysis for Computer Vision
- A Complete Guide of Data Augmentation in Computer Vision
- Hands-on Image Classification in Computer Vision
- Face Recognition in Computer Vision with Implementation
- A Complete Guide to Object Detection with Implementation in Computer Vision
- A Comprehensive Guide to Image Segmentation in Computer Vision
- Pose Estimation in Computer Vision: Concepts & Implementation
- Optical Character Recognition (OCR) in Computer Vision: From Pixels to Text
- Image Generation with DCGANs in Computer Vision
- A Complete Guide to Image Restoration in Computer Vision
- 3D image generation in Computer Vision with implementation
A Complete Guide of Data Augmentation in Computer Vision | Computer Vision
Deep Learning always prefers big data to learn and generalize well from the data. Large data collection is a complex and time-consuming process. So, Data Augmentation comes into place to solve the problem. It is a powerful technique to increase the number of data, enhance the diversity of the dataset, and others. It reduces the overfitting of the model and improves the generalization and robustness of the Deep-learning models.
In the field of Computer Vision, Data Augmentation refers to the process of applying the transformation of images to existing images, creating new images with diversity from existing ones. Today we are going to explore the Data Augmentation technique and how it can be effective in Computer Vision. Let’s start.
Before diving into the details of Data Augmentation, It is important to know how It can be beneficial to us.
The Advantages of Data Augmentation
It offers several advantages in the computer vision and Deep Learning tasks, such as:
- Because of the diversity in data, the model learns the features more robustly and generalizes better to new/unseen data.
- It reduces the chance of overfitting.
- It enables the generation of more training samples without the need for additional data collection.
- It can help to balance the class representation in an imbalanced dataset.
- It helps the model to generalize in real-world variations like lighting, scale, orientation, viewpoint, and others.
- It can improve the performance of the model.
- It saves time as well as encourages models to learn meaningful and more robust features of the data.
Mainly data augmentation techniques improve generalisation and reduce the overfitting of the model. This makes the model robust and makes it useful in real world applications.
Use Cases of Data Augmentations
There are several use cases of Data Augmentation in Computer Vision and Deep Learning tasks. Some of them are given below.

- Image Classification: Augmenting images of various objects with variations in pose, lighting, background and others. It can be performed in medical images to handle variations in patient conditions, imaging equipment, and viewpoints.
- Object Detection: Augment images as well as the coordinates of the object. It can handle class imbalance as well as increase the number of training samples to make the model robust.
- Semantic Segmentation: Augmenting the road scenes, and aerial images in agriculture with variations in weather conditions, lighting, crop health conditions, soil types, and others.
- Object Tracking: Augmenting video frames with variations in lighting, weather conditions, object motion, and others to improve tracking of objects in surveillance videos.
- Gesture Recognition: Augment hand gesture images to capture variations in hand poses, lighting conditions, and backgrounds for robust sign language recognition.
- Face Recognition: Augment facial images with different facial expressions, lighting conditions, and head orientations for better emotion recognition.
Actually there are numerous applications in Computer vision tasks such as defect detection, image generation and so on that can be improved with data augmentation techniques.
Libraries to perform Data Augmentation
In the field of computer vision, there are several libraries and frameworks that provide a number of functionalities for data augmentation.
- Albumentations: It is designed for fast and flexible data augmentations and has the largest set of transformation functions in computer vision. It is a simple interface that can be used in many computer vision tasks such as classification, object detection, segmentation, pose estimation and many others. It can be integrated with Tensorflow, Keras, and Pytorch, not MxNet.
- Augmentor: It is a Python package that provides both data augmentation and basic image processing functionalities. There are many features in augmented like perspective skewing, Rotating, shearing, Elastic Distortion, Shearing, Cropping, Mirroring, Flipping, and many others. It allows a probability parameter for every transformation operation and allows the formation of an augmenting pipeline that chains together a number of operations that are applied stochastically.
- ImgAug: It is similar to augmentor and argumentation but it can be executed with multiple CPU cores. It is easy to use and supports a wide range of augmentation techniques.
- Tensorflow & Keras: They provide ImageDataGenerator or tf.image class that can perform a number of predefined augmentation operations such as rotations, flips, brightness adjustments and others. At the time of training the model, the generator can perform augmentation to the batch of images in real time as the model learns.
- Pytorch: It provides a module named “torchvision.transforms” that can perform a number of augmentation operations such as resizing, cropping, flipping,rotations and others. It defines and applies the transformation technique before model training.
There can be other frameworks like MxNet or libraries like deep augment. Those also can perform several data augmentation techniques to increase dataset and diversity. Hope, you get some idea about data augmentation and libraries associated with it. Now it is high time to know about the various techniques of data augmentations.
Data Augmentation Techniques
There are a lot of data augmentation techniques that can be used in many computer vision tasks. Some of them are described below. We will show all the techniques with the help of the Pytorch library.

- Flipping: It involves creating a mirror image of the original image either horizontally or vertically. This is used to enhance the diversity of the training dataset.
- Rotation: This rotates an image by a certain angle that simulates different viewpoints.
- Brightness Adjustment: It adjusts the brightness of an image by changing pixel values.
- Scaling and Zooming: It scales the image up or down. Zooming in/out adds emphasis to certain parts of the image.
- Cropping: It removes some parts of the images and focuses the model attention to the specific regions.
- Shearing: It skews an image along a certain axis.
- Color Jitter: It introduces random variations in the color channels of an image.
- Noise Addition: Adding random noise to the image. It can be manually adding Gaussian Noise or salt or pepper noise and others.
- Elastic Transformations: These involve applying localized distortions to the image. This is a complex part that needs help from OpenCV.
- Cutout: It masks out some random part of an image.
- Random Erasing: It replaces random parts of an image with noise or a constant value. Similar to Cut Out but with random values instead of a constant value.
- AutoAugment: It uses reinforcement learning to search for the best augmentation policies automatically that identify a sequence of augmentation operations.
- Mixup: It blends two or more images to create a new image and label.
- CutMix: It combines parts of two images to create a new image.
These are the most popular traditional data augmentation techniques that can be used to perform computer vision tasks. Now we are going to implement those techniques in Tensorflow.
Implementation Tradition data Augmentation in Pytorch
Here we perform some data augmentation techniques with the help of the ImageDataGenerator class. Then generate some augmented images and visualize them. You will get the full project code on Google Colab.
import torch
import torchvision.transforms as transforms
from torchvision.utils import make_grid
import matplotlib.pyplot as plt
from PIL import Image
# Load the image you want to augment
image_path = '/content/bOvf94dPRxWu0u3QsPjF_tree.jpg' # Replace with the path to your image
original_image = Image.open(image_path)
# Define a custom data augmentation transform
data_transform = transforms.Compose([
transforms.RandomHorizontalFlip(), # Apply horizontal flipping
transforms.RandomRotation(30), # Rotate images by up to 30 degrees
transforms.ColorJitter(brightness=0.2), # Adjust brightness between -0.2 and 0.2
transforms.RandomAffine(degrees=0, translate=(0.1, 0.1)), # Shift images horizontally and vertically
transforms.RandomAffine(degrees=0, shear=0.2), # Apply shear transformation
transforms.RandomResizedCrop(size=(original_image.size[0], original_image.size[1]), scale=(0.8, 1.2)), # Zoom in/out
transforms.ToTensor(), # Convert to PyTorch tensor
])
# Create a grid to display the original and augmented images
grid = make_grid([data_transform(original_image) for _ in range(10)], nrow=5)
# Visualize original and augmented images
plt.figure(figsize=(15, 10))
plt.imshow(grid.permute(1, 2, 0))
plt.axis('off')
plt.show()
The augmented images look like the below images.

Advanced Data Augmentation technique
Data Augmentation can be performed with the help of deep learning models, sampling or probability distribution. There are some techniques such as Adversarial training, Generative Adversarial Networks, Neural Style Transfer, sampling, probability methods and others. A brief explanation is given below.
Adversarial Machine learning: Adversarial attacks indicate the pixel level changes to the images that can completely change the model prediction. To tackle these attacks in the model, it is needed to augment the data with adversarial training. It involves training a model where the generated examples deceive the model.
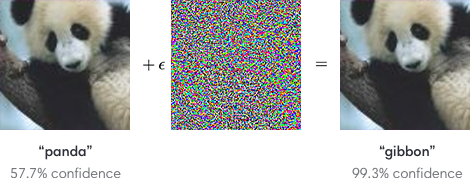
Here in the above image, after some adding noise the model becomes confused and classifies a panda as gibbon. So, these augmented images can be used as training data that make the model robust toward adversarial attacks.
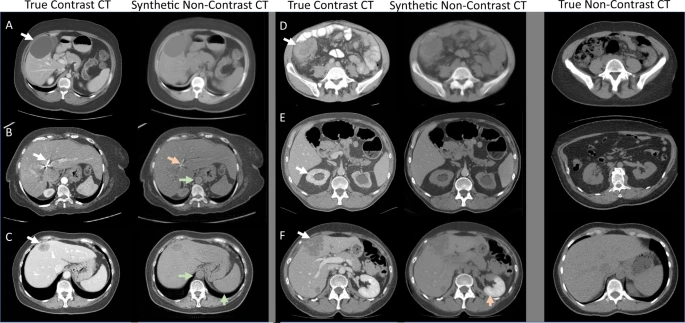
GAN: It generates new data samples that are similar to the original data. So, GANs can be used for data augmentation to increase the number of samples in the training data. There are two parts(Generator and Discriminator) where the generator is responsible for generating new data and the discriminator is responsible for detecting the generated data as fake or real. But it needs a lot of resources and time. An example of Augmented data through CycleGAN is given below.
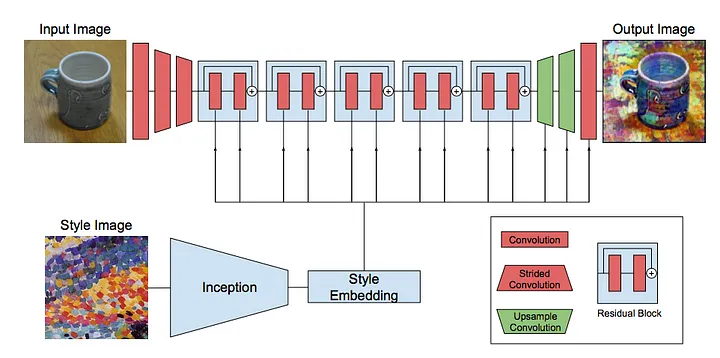
Neural Style transfer: It is a technique that transfers the artistic style of one image onto the content of another image. It keeps the content the same but changes the style of the image that increases the robustness of the model. It can be an efficient way as data augmentation but the process takes more resources and time also. Here the first image takes the style of the second image and generates a new image.
Sampling: Sampling methods include oversampling and undersampling which can create new images. SMOTE (Synthetic Minority Oversampling Technique) is a popular method for generating new data based on sampling. It generates images through interpolation from existing images.
Probabilistic Method: By directly estimating the image distribution and randomly sampling from those distributions, we can generate new images. It is another way that can be used as data augmentation.

Offline vs Online Data Augmentation
- Offline Data Augmentation indicates performing data augmentation on the data before training starts, which means augmented images are generated and saved to the disk before starting the training process. It can be beneficial when you want to use the same set of augmented images for different training runs and it is also fast. But it requires a significant amount of storage space. The diversity is fixed and doesn’t adapt during training (missing out on learning from new variations).
- Online Data Augmentation indicates performing data augmentation during the training of the model. During training, each time a batch of images is performed dynamically the augmentations. It introduces new variations in each epoch that make the model more robust and no need to save the augmented dataset on the disk. But It increases the training time.
- Use Cases of Offline & Online Augmentation: Offline augmentation is useful when you have limited computational resources, want to speed up training, and want to use the same augmented dataset across different training runs. Online augmentation introduces more diversity of the training data and encourages the model to generalize better and also no need to store the data.
Considerations and Limitations
Data augmentation is a technique that improves the robustness and generalization of deep learning models, but there are some considerations and limitations that need to be kept in mind.
- Too many augmentations or overly aggressive transformations can lead the model too specialized for the augmented examples which is called over-augmentation.
- Some datasets like medical images, and satellite images might have intrinsic limitations.
- Not all augmentation techniques work equally well for all types of tasks. Choosing an effective data augmentation technique for a specific task is challenging.
- It can generate low quality images that are not expected.
- Some augmentation techniques require tuning hyperparameters that need to be taken carefully through experimentation to find the optimal values.
To address these considerations and limitations, it’s crucial to experiment with different augmentation techniques,carefully monitor the impact on model performance and ensure that the augmented data aligns with the objectives of the project.
Wrapping Up
- Impact on Model Performance: Data augmentation introduces diversity into the training data, which makes the model more robust and generalizes well in unseen data. It helps the model to reduce the overfitting of the model and perform better in real-world scenarios with varying conditions. The performance of Data augmentation can vary with different datasets and domains. It is an experimental fact. Anyway, A chart is given here to understand the performance difference between with and without Augmentation where traditional Augmentation and GAN based augmentation have been used in those experiments.

Hope, you can feel the importance of data augmentation in computer vision tasks. Now I want to show the model performance of a model after applying specific transformations.
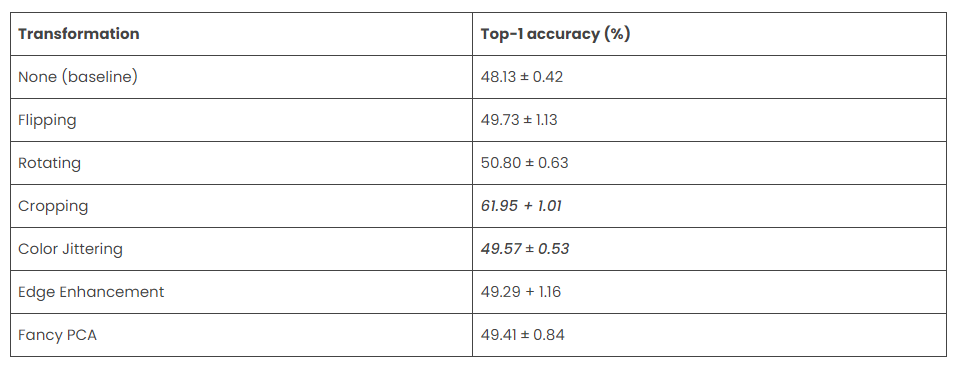
However, the performance after using data augmentation is not the same for all the tasks. You have to perform experiments and monitor the results on your dataset and problem domain.
- Experimenting with Augmentation: If you are interested in experimenting with the model with augmentation technique. Then you can follow some strategies. First start with basic terms like rotations, flips, adjust brightness and see the impact on model performance. Then gradually introduce more complex augmentations like shearing, scaling, and others. Keep track of the performance of each run. Adjust the parameters of the augmentation techniques. If class imbalances are introduced during augmentation,explore techniques like class weighting or oversampling to address the issue. You can also explore Deep Learning and Probabilistic data augmentation techniques to make the model more robust and generalisable.
Conclusion
Data Augmentation plays a vital role in the field of Computer Vision and Deep Learning to make the model more robust, reduce the overfitting of the model, increase the training samples, and increase the diversity of the model. This technique forces the model to learn the underlying patterns of the dataset. That’s why after using it, the model can generalize well on the unseen data. Today we have learned the advantages, use cases, and different techniques of Data augmentation as well as online & offline augmentation. Then some details about the impact on model performance and how to experiment with Data Augmentation.
Hope you have learned the overall idea about data augmentation and use it in your applications. Thanks for reading the article and Happy Learning!!!!!!!